操作 GBase 8s 类型
本主题主要说明特定于 GBase 8s JDBC Driver 中支持的 GBase 8s(而不是 opaque 类型)。要获取关于 opaque 类型的信息,请参阅 与不透明数据类型一起使用。
distinct 数据类型
distinct 类型可映射至底层的基础类型或映射至用户定义的 Java™ 对象。例如,distinct 类型 INT 可映射至 int 或映射至封装该数据表示的 Java 对象。此 Java 对象必须实现 java.sql.SQLData 接口。必须提供如 映射数据类型 中所描述的定制类型映射,来将此 Java 对象映射至对应的 SQL 类型名称。
插入数据示例
下列示例展示一个定义 distinct 类型的 SQL 语句:
CREATE DISTINCT TYPE mymoney AS NUMERIC(10, 2);
CREATE TABLE distinct_tab (mymoney_col mymoney);
下列为映射至基础类型的示例:
String s = "insert into distinct_tab (mymoney_col) values (?)";
System.out.println(s);
pstmt = conn.prepareStatement(s);
...
BigDecimal bigDecObj = new BigDecimal(123.45);
pstmt.setBigDecimal(1, bigDecObj);
System.out.println("setBigDecimal...ok");
pstmt.executeUpdate();
当映射至底层的类型时,GBase 8s JDBC Driver 在客户机侧执行映射,因为数据库服务器提供在底层的类型与 distinct 类型之间隐式的强制转型。
还可将 distinct 类型映射至实现SQLData 接口的 Java™ 对象。下列示例展示一个定义 distinct 类型的 SQL 语句:
CREATE DISTINCT TYPE mymoney AS NUMERIC(10,2)
下列代码将 distinct 类型映射至名为 MyMoney 的 Java 对象:
import java.sql.*;
import com.gbasedbt.jdbc.*;
public class myMoney implements SQLData
{
private String sql_type = "mymoney";
public java.math.BigDecimal value;
public myMoney() { }
public myMoney(java.math.BigDecimal value)
this.value = value;
public String getSQLTypeName()
{
return sql_type;
{
public void readSQL(SQLInput stream, String type) throws
SQLException
{
sql_type = type;
value = stream.readBigDecimal();
{
public void writeSQL(SQLOutput stream) throws SQLException
{
stream.writeBigDecimal(value);
}
// overides Object.equals()
public boolean equals(Object b)
return value.equals(((myMoney)b).value);
}
public String toString()
{
return "value=" + value;
}
}
...
String s - "insert into distinct_tab (mymoney_col) values (?)";
pstmt = conn.prepareStatement(s);
myMoney mymoney = new myMoney();
mymoney.value = new java.math.BigDecimal(123.45);
pstmt.setObject(1, mymoney);
System.out.println("setObject(myMoney)...ok");
pstmt.executeUpdate();
在此情况下,请使用 setObject() 方法,而不是 setBigDecimal() 方法,来插入数据。
检索数据示例
可访存 distinct 类型作为它的底层基础类型,或作为 Java™ 对象,如果以定义类型映射来定义该映射的话。使用前面的示例,可访存该数据作为 Java 对象,如下列示例所示:
java.util.Map customtypemap = conn.getTypeMap();
System.out.println("getTypeMap...ok");
if (customtypemap == null)
{
System.out.println("\n***ERROR: typemap is null!");
return;
}
customtypemap.put("mymoney", Class.forName("myMoney"));
...
String s = "select mymoney_col from distinct_tab order by 1";
try
{
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery(s);
System.out.println("Fetching data ...");
int curRow = 0;
while (rs.next())
{
curRow++;
myMoney mymoneyret = (myMoney)rs.getObject("mymoney_col");
}
System.out.println("total rows expected: " + curRow);
stmt.close();
}
catch (SQLException e)
{
System.out.println("***ERROR: " + e.getErrorCode() + " " +
e.getMessage());
e.printStackTrace();
}
在此情况下,请使用 getObject() 方法来检索数据,而不使用 getBigDecimal() 方法。
不支持的方法
对于 distinct 类型,不支持下列 SQLInput 和 SQLOutput 接口的方法:
- java.sql.SQLInput
- readArray()
- readCharacterStream()
- readRef()
- java.sql.SQLOutput
- writeArray()
- writeCharacterStream(Reader x)
- writeRef(Ref x)
BYTE 和 TEXT 数据类型
本部分描述 GBase 8s BYTE 和 TEXT 数据类型,以及如何以 JDBC API 来操纵这些数据类型的列。
BYTE 数据类型是在不可分的字节流中存储任何数据的简单大对象数据类型。此二进制数据的示例包括电子表格、数字化的语音模式以及视频片段。TEXT 数据类型是存储任何文本数据的简单大对象数据类型。它可同时包含单个的和多字节的字符。
任一数据类型的列都有 231 字节的理论限制,实际限制取决于磁盘容量。
要获取关于 GBase 8s BYTE 和 TEXT 数据类型的更详尽信息,请参阅《GBase 8s SQL 指南:参考》 和《GBase 8s SQL 指南:语法》。
高速缓存大对象
每当从数据库服务器访存 BLOB、CLOB、text 或 byte 类型的对象时,都在客户机内存中高速缓存该数据。如果大对象的大小大于 LOBCACHE 环境变量中的值,则在临时文件中存储大对象数据。要获取关于 LOBCACHE 变量的更多信息,请参阅 大对象的内存管理。
示例:插入或更新数据
要插入至 BYTE 或 TEXT 列,或更新这些列,请从源读取诸如操作系统文件这样的数据流,并将它作为 java.io.InputStream 对象传送至数据库。PreparedStatement 提供设置此 Java™ 输入流的输入参数的方法。当执行该语句时,GBase 8s JDBC Driver 反复地调用该输入流,读取它的内容,并将这些内容作为实际的参数数据传送至数据库。
对于 BYTE 数据类型,请使用 PreparedStatement.setBinaryStream() 方法来设置 InputStream 对象的输入参数。对于 TEXT 数据类型,请使用PreparedStatement.setAsciiStream() 方法。
来自 ByteType.java 程序的下列示例展示如何将操作系统文件 data.dat 的内容插入至 BYTE 数据类型的列内:
try
{
stmt = conn.createStatement();
stmt.executeUpdate("create table tab1(col1 byte)");
}
catch (SQLException e)
{
System.out.println("Failed to create table ..." + e.getMessage());
}
try
{
pstmt = conn.prepareStatement("insert into tab1 values (?)");
}
catch (SQLException e)
{
System.out.println("Failed to Insert into tab: " + e.toString());
}
File file = new File("data.dat");
int fileLength = (int) file.length();
InputStream value = null;
FileInputStream fileinp = null;
int row = 0;
String str = null;
int rc = 0;
ResultSet rs = null;
System.out.println("Inserting data ...\n");
try
{
fileinp = new FileInputStream(file);
value = (InputStream)fileinp;
}
catch (Exception e) {}
try
{
pstmt.setBinaryStream(1,value,10); //set 1st column
}
catch (SQLException e)
{
System.out.println("Unable to set parameter");
}
set_execute();
...
public static void set_execute()
{
try
{
pstmt.executeUpdate();
}
catch (SQLException e)
{
System.out.println("Failed to Insert into tab: " + e.toString());
e.printStackTrace();
}
}
该示例首先创建一个表示操作系统文件 data.dat 的 java.io.File 对象。然后,该示例创建FileInputStream 对象,来从 File 类型的对象读取。将FileInputStream 类型的对象强制转型为它的超类 InputStream,其为 PreparedStatement.setBinaryStream() 方法的第二个参数所需的数据类型。在已准备好的 INSERT 语句上执行 setBinaryStream() 方法,其设置输入流参数。最后,PreparedStatement.executeUpdate() 方法执行,其将 data.dat 操作系统文件的内容插入至 BYTE 类型的列内。
TextType.java 程序展示如何将数据插入至 TEXT 类型的列内。它类似于插入至 BYTE 类型的列内,只使用 setAsciiStream() 方法来设置输入参数,而不是使用 setBinaryStream()。
示例:选择数据
在从表选择至 ResultSet 对象内之后,您可使用 ResultSet.getBinaryStream() 方法来从 BYTE 类型的列检索二进制或 ASCII 数据流。您还可使用ResultSet.getAsciiStream() 方法来从 TEXT 类型的列检索二进制或 ASCII 数据流。两个方法都返回 InputStream 对象,可使用其来读取 chunk 中的数据。
在调用 next() 方法来检索下一行之前,必须读取当前行中返回的流中的所有数据。
来自 ByteType.java 程序的下列示例展示如何从 BYTE 类型的列选择数据,并将数据打印至标准输出设备:
try
{
stmt = conn.createStatement();
rs = stmt.executeQuery("Select * from tab1");
while( rs.next() )
{
row++;
value = rs.getBinaryStream(1);
dispValue(value);
}
}
catch (Exception e) { }
...
public static void dispValue(InputStream in)
{
int size;
byte buf;
int count = 0;
try
{
size = in.available();
byte ary[] = new byte[size];
buf = (byte) in.read();
while(buf!=-1)
{
ary[count] = buf;
count++;
buf = (byte) in.read();
}
}
catch (Exception e)
{
System.out.println("Error occured while reading stream ... \n");
}
}
该示例首先将 SELECT 语句的结果放入 ResultSet 对象内。然后,它执行方法 ResultSet.getBinaryStream(),来将 BYTE 数据检索至 Java™InputStream 对象内。
示例中也包括方法 dispValue() 的 Java 代码,使用其来将该列的内容打印至标准输出设备。dispValue() 方法使用字节数组,且InputStream.read() 方法系统地读取 BYTE 类型列的内容。
TextType.java 程序展示如何从 TEXT 类型列选择数据。它类似于从 BYTE 类型列选择,只使用 getAsciiStream() 方法,而不使用getBinaryStream()。
SERIAL 和 SERIAL8 数据类型
通过方法 getSerial() 和 getSerial8(),GBase 8s JDBC Driver 提供对 GBase 8s SERIAL 和 SERIAL8 数据类型的支持,其为 java.sql.Statement接口实现的一部分。
由于 SERIAL 和 SERIAL8 数据类型没有来自 java.sql.Types 类的向任何 JDBC API 数据类型的明显映射,因此,您必须将特定于 GBase 8s 的类导入至 Java™ 程序内,以处理 SERIAL 和 SERIAL8 列。要这么做,请将下列导入行添加至 Java 程序:
import com.gbasedbt.jdbc.*;
在 INSERT 语句之后,请使用 getSerial() 方法,来返回自动插入至表的 SERIAL 列内的序列值。在 INSERT 语句之后,请使用 getSerial8() 方法,来返回自动插入至表的 SERIAL8 列内的序列值。如果任何下列条件为真,则这些方法返回 0:
- 最后的语句不是 INSERT 语句。
- 正在插入至其内的表不包含 SERIAL 或 SERIAL8 列。
- 尚未执行 INSERT 语句。
在 CREATE TABLE 语句之后,如果执行 getSerial() 或 getSerial8() 方法,则该方法缺省地返回 1(假定新表包括一个 SERIAL 或 SERIAL8 列)。如果该表不包含 SERIAL 或 SERIAL8 列,则该方法返回 0。如果指定新的序列起始编号,则该方法返回该编号。
如果您想要使用 getSerial() 和 getSerial8() 方法,则必须将 Statement 或 PreparedStatement 对象强制转型为 IfmxStatement,其为特定于GBase 8s 的 Statement 接口的实现。下列示例展示如何执行该强制转型:
cmd = "insert into serialTable(i) values (100)";
stmt.executeUpdate(cmd);
System.out.println(cmd+"...okay");
int serialValue = ((IfmxStatement)stmt).getSerial();
System.out.println("serial value: " + serialValue);
如果您想要将连续的序列值插入至 SERIAL 或 SERIAL8 数据类型的列内,则请为 INSERT 语句中的 SERIAL 或 SERIAL8 列指定值 0。当将该列设置为 0 时,数据库服务器指定仅次于最高值的值。
要获取关于 GBase 8s SERIAL 和 SERIAL8 数据类型的更详尽信息,请参阅《GBase 8s SQL 指南:参考》 和《GBase 8s SQL 指南:语法》 。
BIGINT 和 BIGSERIAL 数据类型
BIGINT 和 BIGSERIAL 数据类型与 INT8 和 SERIAL8 数据类型有相同的值域。然而,BIGINT 和 BIGSERIAL 比 INT8 和 SERIAL8 更利于存储和计算。
BIGINT 和 BIGSERIAL 数据类型都映射至 java.sql.Types 类中的 BIGINT Java™ 类型。当从数据库检索数据时,BIGINT 和 BIGSERIAL 数据类型映射至 long Java 类型。
通过 getBigSerial() ,GBase 8s JDBC Driver 提供对 GBase 8s BIGSERIAL 和 BIGINT 数据类型的支持,其为 java.sql.Statement 接口的一部分。
由于 BIGSERIAL 和 BIGINT 数据类型没有向来自 java.sql.Types 类的 JDBC API 数据类型的明显映射,因此,您必须将特定于 GBase 8s 的类导入至 Java 程序,来处理 BIGSERIAL 和 BIGINT 列。要这么做,请将下列导入行添加至 Java 程序:
import com.gbasedbt.jdbc.*;
在 INSERT 语句之后,请使用 getBigSerial() 方法来返回插入至表的 BIGSERIAL 或 BIGINT 列内的值。
如果您想要使用 getBigSerial() 方法,则必须将 Statement 或 PreparedStatement 对象强制转型为 IfmxStatement,其为特定于 GBase 8s的 Statement 接口的实现。下列示例展示如何执行强制转型:
cmd = "insert into serialTable(i) values (100)";
stmt.executeUpdate(cmd);
System.out.println(cmd+"...okay");
int serialValue = ((IfmxStatement)stmt).getSerial();
System.out.println("serial value: " + serialValue);
这些类型是 com.gbasedbt.lang.IfxTypes 类的一部分。要了解 IfxTypes 常量和对应的 GBase 8s 数据类型,请参阅 IfxTypes 类 表。
INTERVAL 数据类型
GBase 8s INTERVAL 数据类型存储表示时间跨度的值。INTERVAL 数据类型由两个类型组成:年-月间隔和日-时间间隔。年-月间隔可表示年和月的跨度,日-时间间隔可表示日、小时、分、秒和一秒的几分之一的跨度。要获取关于 INTERVAL 数据类型以及 qualifier、precision 和 fraction 的定义的更多信息,请参阅下列出版物:
- GBase 8s SQL 指南:教程
- GBase 8s SQL 指南:参考
- GBase 8s SQL 指南:语法
Interval 类
com.gbasedbt.lang.Interval类是对 JDBC 规范的特定于 GBase 8s 的扩展。Interval 是 INTERVAL 数据类型的基础类。Interval 有两个子类:IntervalYM(对于年-月限定符)和 IntervalDF(对于日-时间限定符)。使用这些子类来创建和操纵 INTERVAL 数据类型。
许多 Interval、IntervalYM 和IntervalDF构造函数采用 Connection对象作为参数。这将 CLIENT_LOCALE 环境变量的值传至Interval、IntervalYM或IntervalDF 对象,如果抛出异常,则其允许显示本地化的错误消息。要获取更多信息,请参阅 支持全球化的错误消息。
要获取本部分中关于字符串 INTERVAL 格式的信息,请参阅《GBase 8s SQL 指南:语法》。
二进制限定符的变量
可使用字符串限定符来操纵 INTERVAL 数据类型,但使用二进制限定符会导致更快的性能。在 Interval 基础类中定义下列变量,并表示二进制限定符中字段的时间单位(开始和结束代码)。要使用这些变量,请实例化 IntervalYM 和 IntervalDF 类的对象,其从 Interval 基础类继承这些变量。
TU_YEAR
YEAR 限定符字段的时间单位
TU_MONTH
MONTH 限定符字段的时间单位
TU_DAY
DAY 限定符字段的时间单位
TU_HOUR
HOUR 限定符字段的时间单位
TU_MINUTE
MINUTE 限定符字段的时间单位
TU_SECOND
SECOND 限定符字段的时间单位
TU_FRAC
领头的 FRACTION 限定符字段的时间单位
TU_F1
FRACTION 的第一个位置的结束字段的时间单位
TU_F2
FRACTION 的第二个位置的结束字段的时间单位
TU_F3
FRACTION 的第三个位置的结束字段的时间单位
TU_F4
FRACTION 的第四个位置的结束字段的时间单位
TU_F5
FRACTION 的第五个位置的结束字段的时间单位
Interval 方法
可使用 Interval 方法来抽取关于二进制限定符的信息。要使用这些方法,请实例化 IntervalYM和 IntervalDF 类的对象,其从 Interval 基础类继承这些变量。
您可执行的某些任务和可使用的方法如下:
- 抽取限定符的长度:
public static byte getLength(short qualifier)
- 从限定符抽取开始字段代码(TU_XXX 变量之一):
public static byte getStartCode(short qualifier)
- 限定符抽取结束字段代码(TU_XXX 变量之一):
public static byte getEndCode(short qualifier)
- 取得对应于间隔的一部分的 TU_XXX 值的字符串值(例如,getFieldName(TU_YEAR) 返回字符串 year):
public static String getFieldName(byte code)
- 取得该间隔的完整名称作为字符串,采用限定符作为输入:
public static String getIfxTypeName(int type,short qualifier)
- 取得 INTERVAL 数据类型的 FRACTION 部分中的数字数:
public static byte getScale(short qualifier)
- 从长度、开始代码(TU_XXX)和结束代码(TU_XXX)创建二进制限定符:
public static short getQualifier(byte length, byte startCode, byte endCode) throws SQLException
例如,getQualifier(4, TU_YEAR, TU_MONTH) 创建 YEAR TO MONTH 限定符的二进制表示。
IntervalYM 类
com.gbasedbt.lang.IntervalYM 类允许您操纵年-月间隔。
IntervalYM 构造函数
缺省的构造函数定义如下:
public IntervalYM() throws SQLException
如果抛出异常,则请使用该构造函数的第二个版本来显示本地化的错误消息:
public IntervalYM(Connection conn) throws SQLException
请使用下列构造函数来从特定的输入值创建年-月间隔:
- 两个时间戳,返回等于 Timestamp1 - Timestamp2 的 IntervalYM 值:
public IntervalYM(Timestamp t1, Timestamp t2) throws SQLException
public IntervalYM (Timestamp t1, Timestamp t2, Connectionconn) throws SQLException
第二个版本允许您支持本地化的错误消息。
- 年和月值(将大型月份值转换为年):
public IntervalYM(int years, int months) throws SQLException
public IntervalYM(int years, int months,Connection conn) throws SQLException
第二个版本允许您支持本地化的错误消息。
- 月份值和编码的限定符:
public IntervalYM(int months, short qualifier, Connection conn) throws SQLException
要指定限定符,可使用 Interval 方法 中描述的 getQualifier() 方法。此构造函数支持本地化的错误消息。
- 字符串:
public IntervalYM(String string) throws SQLException
public IntervalYM(String string, Connection conn) throws SQLException
第二个版本允许您支持本地化的错误消息。
- 字符串和限定符:
public IntervalYM(String string, short qualifier, Connection conn) throws SQLException
要指定限定符,可使用 Interval 方法 中描述的 getQualifier() 方法。此构造函数支持本地化的错误消息。
- 字符和限定符信息:
public IntervalYM(String string, int length, byte startCode, byte endCode) throws SQLException
public IntervalYM(String string, int length, byte startCode, byte endCode, Connection conn) throws SQLException
第二个版本允许您支持本地化的错误消息。
IntervalYM 方法
下列方法允许您操纵年-月间隔。(您还可使用前面描述的 Interval 方法。)您可以 IntervalYM 方法执行的某些任务包括下列:
-
比较两个间隔:
boolean equals(Object other)
boolean greaterThan(IntervalYM other)
boolean lessThan(IntervalYM other) -
从其设置间隔的值:
- 字符串:
void fromString(String other)
void set(String string)- 年和月值(将大型月值转换为年):
void set(int years, int months)- 两个时间戳:
void set(Timestamp t1, Timestamp t2) -
设置间隔的限定符:
- 从长度、开始代码和结束代码:
void setQualifier(int length, byte startcode, byte endcode)- 使用现有的限定符:
void setQualifier(short qualifier) -
取得间隔中的月数:
long getMonths() -
以 yyyy-mm 格式来创建间隔的字符串表示:
String toString()
字段的显示依赖于限定符。以空格替代开头的零。
IntervalDF 类
com.gbasedbt.lang.IntervalDF 类允许您操纵间隔。
IntervalDF 构造函数
定义的缺省构造函数如下:
public IntervalDF() throws SQLException
如果抛出异常,请使用缺省构造函数的第二个版本,来显示本地化的错误消息:
public IntervalDF(Connection conn) throws SQLException
请使用下列构造函数,来创建来自特定的输入值的间隔:
- 两个时间戳 t1 和 t2,返回等于 t1 - t2 的 IntervalDF 值:
public IntervalDF(Timestamp t1, Timestamp t2)
throws SQLException
public IntervalDF(Timestamp t1, Timestamp t2, Connection conn)
throws SQLException
第二个版本允许您支持本地化的错误消息。
- 秒和纳秒数(将大型秒值转换为分、小时或天):
public IntervalDF(long seconds, long nanos)
throws SQLException
public IntervalDF(long seconds, long nanos, Connection conn)
throws SQLException
第二个版本允许您支持本地化的错误消息。
- 秒数、纳秒数和限定符:
public IntervalDF(long seconds, long nanos, short qualifier)
throws SQLException
public IntervalDF(long seconds, long nanos, short qualifier, Connection conn)
throws SQLException
要指定限定符,可使用 Interval 方法 中描述的 getQualifier() 方法。第二个版本允许您支持本地化的错误消息。
- 字符串:
public IntervalDF(String string)
throws SQLException
public IntervalDF(String string, Connection conn)
throws SQLException
第二个版本允许您支持本地化的错误消息。
当使用这些构造函数时,将缺省的限定符设置为下列值:
领头的字段精度:2 开始代码:TU_DAY 结束代码:TU_F5
要获取关于字符串 INTERVAL 格式的信息,请参阅《GBase 8s SQL 指南:语法》。
- 字符串和限定符:
public IntervalDF(String string, short qualifier)
throws SQLException
public IntervalDF(String string, short qualifier, Connection conn)
throws SQLException
要指定限定符,可使用 Interval 方法 中描述的 getQualifier() 方法。第二个版本允许您支持本地化的错误消息。
- 字符串和限定符信息:
public IntervalDF(String string, int length, byte startcode, byte endcode)
throws SQLException
public IntervalDF(String string, int length, byte startcode, byte endcode, Connection conn) throws SQLException
第二个版本允许您支持本地化的错误消息。
IntervalDF 方法
下列方法允许您操纵间隔。(您还可使用 Interval 方法,如前描述。)您可执行的任务和可使用的方法如下:
-
比较两个间隔:
boolean equals(Object other)
boolean greaterThan(IntervalDF other)
boolean lessThan(IntervalDF other) -
从其设置间隔的值:
- 字符串:
void fromString(String other)
void set(String string)- 秒和纳秒值(将大型秒值转换为分钟、小时或天):
void set(long seconds, long nanos)- 两个时间戳:
void set(Timestamp t1, Timestamp t2) -
从长度、开始代码和结束代码设置限定符:
void setQualifier(int length, byte startcode, byte endcode) -
取得间隔中的纳秒数:
long getNanoSeconds() -
取得间隔中的秒数:
long getSeconds() -
以格式 ddddd hh:mm:ss.nano 创建间隔的字符串表示:
String toString()字段显示依赖于限定符。以空格替代开头的零。
Interval 示例
包括在 GBase 8s JDBC Driver 中的 Intervaldemo.java 程序展示如何插入以及如何从两类 INTERVAL 数据类型选择。
集合和数组
JDBC 3.0 规范仅描述一个方法,来交换 Java™ 客户机与关系型数据库之间的集合数据:数组。
由于数组接口不包括构造函数,因此,GBase 8s JDBC Driver 包括一个扩展,允许在 PreparedStatement.setObject() 和ResultSet.getObject() 方法中使用 java.util.Collection 对象。
如果您更愿意使用 Array 对象,则请使用 PreparedStatement.setArray() 和 ResultSet.getArray() 方法。Collection 对象更易于使用,但Array 对象符合 JDBC 3.0 标准。
在缺省情况下,在访存期间,驱动程序将 LIST 列映射至 java.util.ArrayList 对象,而将 SET 和 MULTISET 列映射至 java.util.HashSet 对象。您可覆盖这些缺省值,但您使用的类必须实现 java.util.Collection 接口。
要覆盖此缺省的映射,可使用 java.util.Collection 接口中的其他类,诸如 TreeSet 类。还可创建实现 java.util.Collection 接口的自己的类。在任一情况下,您都必须使用 Connection.setTypeMap() 方法来提供定制的类型映射。
在 INSERT 操作期间,必须将作为 java.util.Set 接口实例的任何 java.util.Collection 对象映射至 GBase 8s MULTISET 数据类型。将java.util.List 接口的实例映射至 GBase 8s LIST 数据类型。通过创建定制的类型映射,可覆盖这些缺省值。
要获取关于定制的类型映射的信息,请参阅 映射数据类型。
set 是无序的定义。如果使用 HashSet 对象来选择集合数据,则 HashSet 对象中元素的顺序可能与插入该 set 时指定的顺序不同。例如,如果数据库服务器上的数据为 set {1, 2, 3},则检索至 HashSet 对象内的数据可能为 {3, 2, 1},或任何其他顺序。
下列部分中所有示例的完整版本位于您安装驱动程序处的 complex-types 目录中。要获取更多信息,请参阅 示例代码文件。
集合示例
下列为样例数据库模式:
create table tab ( a set(integer not null), b integer);
insert into tab values ("set{1, 2, 3}", 10);
下列为使用 java.util.HashSet 对象的访存示例:
java.util.HashSet set;
PreparedStatement pstmt;
ResultSet rs;
pstmt = conn.prepareStatement("select * from tab");
System.out.println("prepare ... ok");
rs = pstmt.executeQuery();
System.out.println("executeQuery ... ok");
rs.next();
set = (HashSet) rs.getObject(1);
System.out.println("getObject() ... ok");
/* The user can now use HashSet.iterator() to extract
* each element in the collection.
*/
Iterator it = set.iterator();
Object obj;
Class cls = null;
int i = 0;
while (it.hasNext())
{
obj = it.next();
if (cls == null)
{
cls = obj.getClass();
System.out.println(" Collection class: " + cls.getName());
}
System.out.println(" element[" + i + "] = " +
obj.toString());
i++;
}
pstmt.close();
在此示例的 set = (HashSet) rs.getObject(1) 语句中, GBase 8s JDBC Driver 取得列 1 的类型。由于它是 SET 类型,因此,实例化一HashSet 对象。接下来,将每一集合元素转换至 Java™ 对象内,并插入至集合内。
下列访存示例使用 java.util.TreeSet 对象:
java.util.TreeSet set;
PreparedStatement pstmt;
ResultSet rs;
/*
* Fetch a SET as a TreeSet instead of the default
* HashSet. In this example a new java.util.Map object has
* been allocated and passed in as a parameter to getObject().
* Connection.getTypeMap() could have been used as well.
*/
java.util.Map map = new HashMap();
map.put("set", Class.forName("java.util.TreeSet"));
System.out.println("mapping ... ok");
pstmt = conn.prepareStatement("select * from tab");
System.out.println("prepare ... ok");
rs = pstmt.executeQuery();
System.out.println("executeQuery ... ok");
rs.next();
set = (TreeSet) rs.getObject(1, map);
System.out.println("getObject(Map) ... ok");
/* The user can now use HashSet.iterator() to extract
* each element in the collection.
*/
Iterator it = set.iterator();
Object obj;
Class cls = null;
int i = 0;
while (it.hasNext())
{
obj = it.next();
if (cls == null)
{
cls = obj.getClass();
System.out.println(" Collection class: " + cls.getName());
}
System.out.println(" element[" + i + "] = " +
obj.toString());
i++;
}
pstmt.close();
在 map.put("set", Class.forName("java.util.TreeSet" )); 语句中,覆盖 set = HashSet 的缺省映射。
在 set = (TreeSet)rs.getObject(1, map) 语句中,GBase 8s JDBC Driver 为列 1 取得类型,并发现它是 SET 对象。然后,驱动程序查找类型映射信息,找到 TreeSet,并实例化一 TreeSet 对象。接下来,将每一集合元素映射至 Java 对象,并插入至集合内。
下列示例展示插入。此示例将 set (0, 1, 2, 3, 4) 插入至 SET 列内:
java.util.HashSet set = new HashSet();
Integer intObject;
int i;
/* Populate the Java collection */
for (i=0; i < 5; i++)
{
intObject = new Integer(i);
set.add(intObject);
}
System.out.println("populate java.util.HashSet...ok");
PreparedStatement pstmt = conn.prepareStatement
("insert into tab values (?, 20)");
System.out.println("prepare...ok");
pstmt.setObject(1, set);
System.out.println("setObject()...ok");
pstmt.executeUpdate();
System.out.println("executeUpdate()...ok");
pstmt.close();
此示例中的 pstmt.setObject(1, set) 语句首先序列化集合的每一元素。接下来,构造类型信息作为每一元素转换为 Java 对象。如果该集合中任何元素的类型都与第一个元素的类型不匹配,则抛出异常。将类型信息发送至数据库服务器。
数组示例
下列是一个样例数据库模式:
CREATE TABLE tab (a set(integer not null), b integer);
INSERT INTO tab VALUES ("set{1,2,3}", 10);
下列示例使用 java.sql.Array 对象访存数据:
PreparedStatement pstmt = conn.prepareStatement("select a from tab");
System.out.println("prepare ... ok");
ResultSet rs = pstmt.executeQuery();
System.out.println("executeQuery ... ok");
rs.next();
java.sql.Array array = rs.getArray(1);
System.out.println("getArray() ... ok");
pstmt.close();
/*
* The user can now materialize the data into either
* an array or else a ResultSet. If the collection elements
* are primitives then the array should be an array of primitives,
* not Objects. Mapping data can be provided at this point.
*/
Object obj = array.getArray((long) 1, 2);
int [] intArray = (int []) obj; // cast it to an array of ints
int i;
for (i=0; i < intArray.length; i++)
{
System.out.println("integer element = " + intArray[i]);
}
pstmt.close();
java.sql.Array array = rs.getArray(1) 语句实例化 java.sql.Array 对象。在此点不转换数据。
Object obj = array.getArray((long)1, 2) 语句将数据转换为整数的数组(int 类型,不是 Integer 对象)。由于未以索引和计数值调用getArray() 方法,因此,仅返回数据的子集。
命名的和未命名的行
JDBC 3.0 规范引用一称为 结构化类型或 struct 的 SQL 类型,其等同于 GBase 8s 命名的行。该规范定义在 Java™ 客户机与关系型数据库之间交换结构化类型数据的方法:
- 使用 SQLData 接口。每个命名的行类型一个单个 Java 类,实现 SQLData 接口。对于命名的行中每一元素,该类有一个成员。
- 使用 Struct 接口。此接口为命名的行中每一元素实例化必要的 Java 对象,并构建一个java.util.Object Java 对象的数组。
对于访存了的命名的行,GBase 8s JDBC Driver 是实例化一个 Java 对象,还是一个 Struct 对象,依赖于是否有定制的类型映射条目,如下所示:
- 对于 Connection.getTypeMap() 映射中的命名的行,如果有一个条目,或如果您使用 getObject() 方法提供了类型映射,则实例化单个 Java 对象。
- 对于 Connection.getTypeMap() 映射中命名的行,如果没有条目,且如果您未使用 getObject() 方法提供类型映射,则实例化一个Struct对象。
始终将未命名的行访存至 Struct 对象内。
不论使用 SQLData 还是 Struct 接口,如果命名的行或未命名的行包含一 opaque 数据类型列,则必须有一个它的类型映射条目。如果正在使用 Struct 接口来访问包含 opaque 数据类型列的行,则您需要该 opaque 数据类型列的定制类型映射,但不是对于整个行。
要获取关于定制类型映射的更多信息,请参阅 映射数据类型。
间隔和集合支持
扩展 java.sql.SQLOutput 和 java.sql.SQLInput 方法,来支持命名的和未命名的行中的 Collection 和 Interval 对象。这些扩展包括下列方法:
- 如果数据为 set、list 或 multiset 数据类型,则 com.gbasedbt.jdbc.IfmxComplexSQLInput.readObject() 方法返回恰当的java.util.Collection 对象。
- 对于 interval 数据类型,com.gbasedbt.jdbc.IfmxComplexSQLInput.readInterval() 方法是返回恰当的 IntervalYM 还是 IntervalDF 对象,依赖于限定符。
- com.gbasedbt.jdbc.IfmxComplexSQLOutput.writeObject() 方法接受从 java.util.Collection 接口,或从 IntervalYM 和 IntervalDF 对象派生的对象。
不支持的方法
不支持下列 SQLInput 方法将 ROW 列选择至实现 SQLData 的 Java™ 对象内:
- readByte()
- readCharacterStream()
- readRef()
不支持下列 SQLOutput 方法将实现 SQLData 的 Java 对象插入至 ROW 列内:
- writeByte(byte)
- writeCharacterStream(java.io.Reader x)
- writeRef(Ref x)
SQLData 接口
命名的行的 Java™ 类必须实现 SQLData 接口。对于命名的行中每一元素,该类必须有一个成员,但除了这些之外可有其他成员。这些成员可以按任何顺序,且不要公开。
对于命名的行,Java 类必须实现 writeSQL()、readSQL() 和 getSQLTypeName() 方法,如在 SQLData 接口中定义的那样,但可实现附加的方法。可使用 ClassGenerator 实用程序来创建该类;要获取更多信息,请参阅 ClassGenerator 实用程序。
要以命名的行来链接此 Java 类,请使用 Connection.setTypeMap() 方法或 getObject() 方法,来创建定制的类型映射。要获取关于类型映射的更多信息,请参阅 映射数据类型。
不可使用 SQLData 接口来访问未命名的行。
SQLData 示例
本部分中所有示例的完整版本位于安装了驱动程序处的 demo/complex-types 目录中。要获取更多信息,请参阅 示例代码文件。
下列示例包括一个实现 java.sql.SQLData 接口的 Java™ 类。
这里是样例数据库模式:
CREATE ROW TYPE fullname_t (first char(20), last char(20));
CREATE ROW TYPE person_t (id int, name fullname_t, age int);
CREATE TABLE teachers (person person_t, dept char (20));
INSERT INTO teachers VALUES ("row(100, row('Bill', 'Smith'), 27)", "physics");
这是 fullname Java 类:
import java.sql.*;
public class fullname implements SQLData
{
public String first;
public String last;
private String sql_type = "fullname_t";
public String getSQLTypeName()
{
return sql_type;
}
public void readSQL (SQLInput stream, String type) throws
SQLException
{
sql_type = type;
first = stream.readString();
last = stream.readString();
}
public void writeSQL (SQLOutput stream) throws SQLException
{
stream.writeString(first);
stream.writeString(last);
}
/*
* Function not required by SQLData interface, but makes
* it easier for displaying results.
*/
public String toString()
{
String s = "fullname: ";
s += "first: " + first + " last: " + last;
return s;
}
}
这是person Java 类:
import java.sql.*;
public class person implements SQLData
{
public int id;
public fullname name;
public int age;
private String sql_type = "person_t";
public String getSQLTypeName()
{
return sql_type;
}
public void readSQL (SQLInput stream, String type) throws SQLException
{
sql_type = type;
id = stream.readInt();
name = (fullname)stream.readObject();
age = stream.readInt();
}
public void writeSQL (SQLOutput stream) throws SQLException
{
stream.writeInt(id);
stream.writeObject(name);
stream.writeInt(age);
}
public String toString()
{
String s = "person:";
s += "id: " + id + "\n";
s += " name: " + name.toString() + "\n";
s += " age: " + age + "\n";
return s;
}
}
这里是访存命名的行的示例:
java.util.Map map = conn.getTypeMap();
conn.setTypeMap(map);
map.put("fullname_t", Class.forName("fullname"));
map.put("person_t", Class.forName("person"));
...
PreparedStatement pstmt;
ResultSet rs;
pstmt = conn.prepareStatement("select person from teachers");
System.out.println("prepare ...ok");
rs = pstmt.executeQuery();
System.out.println("executetQuery()...ok");
while (rs.next())
{
person who = (person) rs.getObject(1);
System.out.println("getObject()...ok");
System.out.println("Data fetched:");
System.out.println("row: " + who.toString());
}
pstmt.close();
通过 Connection 对象,conn.getTypeMap() 方法从 java.util.Map 对象返回命名的行映射信息。
map.put() 方法注册数据库服务器上嵌套的命名的行 fullname_t 与 Java 类 fullname 之间的映射,以及数据库服务器上命名的行 person_t与 Java 类 person之间的映射。
person who = (person) rs.getObject(1) 语句将命名的行检索至 Java 对象 who 内。GBase 8s JDBC Driver 承认此对象 who 是命名的行、distinct 类型或 opaque 类型,因为数据库服务器发送的信息有扩展的名称 person_t。
驱动程序查找person_t,并发现它是命名的行。驱动程序以键 person_t调用 map.get() 方法,其返回person 类对象。实例化类 person 的一个对象。
person 类中的 readSQL() 方法调用定义在 SQLInput接口中的方法,来将 ROW 列中每一字段转换为 Java 对象,并将每一指定为 person 类中的一个成员。
下列展示一个方法,用于使用 setObject() 方法将 Java 对象插入至命名的行列内:
java.util.Map map = conn.getTypeMap();
map.put("fullname_t", Class.forName("fullname"));
map.put("person_t", Class.forName("person"));
...
PreparedStatement pstmt;
System.out.println("Populate person and fullname objects");
person who = new person();
fullname name = new fullname();
name.last = "Jones";
name.first = "Sarah";
who.id = 567;
who.name = name;
who.age = 17;
String s = "insert into teachers values (?, 'physics')";
pstmt = conn.prepareStatement (s);
System.out.println("prepared...ok");
pstmt.setObject(1, who);
System.out.println("setObject()...ok");
int rowcount = pstmt.executeUpdate();
System.out.println("executeUpdate()...ok");
pstmt.close();
通过Connection对象,conn.getTypeMap() 方法从 java.util.Map对象返回命名的行映射信息。
map.put() 方法注册数据库服务器上嵌套的命名的行 fullname_t 与 Java 类 fullname之间的映射,以及数据库服务器上命名的行 person_t与 Java 类 person之间的映射。
GBase 8s JDBC Driver 认可对象 who 实现 SQLData 接口,因此,它是命名的行、 distinct 类型,或 opaque 类型。对于此对象,GBase 8s JDBC Driver 调用 getSQLTypeName() 方法(需要类实现SQLData接口),其返回 person_t。驱动程序查找person_t,并发现它是命名的行。
对于类中的每一成员,person类中的 writeSQL() 方法调用对应的 SQLOutput.writeXXX() 方法,将其每一都映射至命名的行person_t中的一个字段。该类中的 writeSQL() 方法包含对 SQLOutput.writeObject(name) 和 SQLOutput.writeInt(id) 方法的调用。序列化类person的每一成员,并写至流内。
Struct 接口
JDBC 资料未指定 Struct 对象可作为 PreparedStatement.setObject() 方法的参数。然而,GBase 8s JDBC Driver 可处理实现 java.sql.Struct接口的 PreparedStatement.setObject() 或 ResultSet.getObject() 方法处理的任何对象。
必须使用 Struct 接口来访问未命名的行。
无需创建自己的类来实现 java.sql.Struct 接口。然而,在您可插入或更新 ROW 数据之前,必须执行访存来检索 ROW 数据和类型信息。GBase 8s JDBC Driver 自动地调用 getSQLTypeName() 方法,其返回命名的行的类型名称,或未命名的行的行定义。
如果创建自己的类来实现 Struct 接口,则您创建的类必须实现所有 java.sql.Struct 方法,包括 getSQLTypeName() 方法。您可选择getSQLTypeName() 方法返回什么。
虽然必须返回未命名的行的行定义,但是,您可返回命名的行的行名称或行定义。每一个都有优点:
- 行定义。驱动程序无需为了类型信息查询数据库服务器。此外,返回的行定义不必与命名的行定义完全匹配,因为数据库服务器提供强制转型,如果需要的话。例如,如果想要使用字符串来插入至行中的 opaque 类型,则这是有用的。
- 行名称。如果用户定义的例程采用命名的行作为参数,则签名必须匹配,因此,您必须在命名的行中传递。
要获取关于用户定义的例程的更多信息,请参数下列出版物:J/Foundation 开发者指南(特定于 Java™ 的信息);GBase 8s 用户定义的例程和数据类型开发者指南 和 GBase 8s SQL 指南:参考(都是关于用户定义的例程的通用信息);GBase 8s SQL 指南:语法(创建和调用用户定义的例程的语法)。
如果为命名的行使用 Struct 接口,并为命名的行提供类型映射信息,则当调用 ResultSet.getObject() 方法时,会产生 ClassCastException 信息,因为 Java 不可在 SQLData 对象与 Struct 对象之间强制转型。
Struct 示例
本部分中所有示例的完整版本位于安装了驱动程序处的 demo/complex-types 目录中。要获取更多信息,请参阅 示例代码文件。
此示例访存未命名的 ROW 列。这里是样例数据库模式:
CREATE TABLE teachers
(
person row(
id int,
name row(first char(20), last char(20)),
age int
),
dept char(20)
);
INSERT INTO teachers VALUES ("row(100, row('Bill', 'Smith'), 27)", "physics");
这是该示例的剩余部分:
PreparedStatement pstmt;
ResultSet rs;
pstmt = conn.prepareStatement("select person from teachers");
System.out.println("prepare ...ok");
rs = pstmt.executeQuery();
System.out.println("executetQuery()...ok");
rs.next();
Struct person = (Struct) rs.getObject(1);
System.out.println("getObject()...ok");
System.out.println("\nData fetched:");
Integer id;
Struct name;
Integer age;
Object[] elements;
/* Get the row description */
String personRowType = person.getSQLTypeName();
System.out.println("person row description: " + personRowType);
System.out.println("");
/* Convert each element into a Java object */
elements = person.getAttributes();
/*
* Run through the array of objects in 'person' getting out each structure
* field. Use the class Integer instead of int, because int is not an object.
*/
id = (Integer) elements[0];
name = (Struct) elements[1];
age = (Integer) elements[2];
System.out.println("person.id: " + id);
System.out.println("person.age: " + age);
System.out.println("");
/* Convert 'name' as well. */
/* get the row definition for 'name' */
String nameRowType = name.getSQLTypeName();
System.out.println("name row description: " + nameRowType);
/* Convert each element into a Java object */
elements = name.getAttributes();
/*
* run through the array of objects in 'name' getting out each structure
* field.
*/
String first = (String) elements[0];
String last = (String) elements[1];
System.out.println("name.first: " + first);
System.out.println("name.last: " + last);
pstmt.close();
如果列 1 是 ROW 类型,且没有扩展的数据类型名称(如果它是命名的行的话),则 Struct person = (Struct) rs.getObject(1) 语句实例化一个 Struct 对象。
elements = person.getAttributes(); 语句执行下列活动:
- 以正确的元素数分配一个 java.lang.Object 对象的数组
- 将该行中每一元素转换为一 Java™ 对象
如果该元素为 opaque 类型,则必须在 Connection 对象中提供类型映射,或在对 getAttributes() 方法的调用中传递一个java.util.Map 对象。
String personrowType = person.getSQLTypeName(); 语句返回行类型信息。如果此类型为命名的行,则该语句返回名称。由于类型不是命名的行,因此,该语句返回行定义:row(int id, row(first char(20), last char(20)) name, int age).
然后,该示例进入未命名的行 name 的后续步骤,如同对未命名的行 person 一样。
下列示例使用用户创建的类 GenericStruct,其实现 java.sql.Struct 接口。作为替代,您可使用从 ResultSet.getObject() 方法返回的 Struct 对象,而不是 GenericStruct 类。
import java.sql.*;
import java.util.*;
public class GenericStruct implements java.sql.Struct
{
private Object [] attributes = null;
private String typeName = null;
/*
* Constructor
*/
GenericStruct() { }
GenericStruct(String name, Object [] obj)
{
typeName = name;
attributes = obj;
}
public String getSQLTypeName()
{
return typeName;
}
public Object [] getAttributes()
{
return attributes;
}
public Object [] getAttributes(Map map) throws SQLException
{
// this class shouldn't be used if there are elements
// that need customized type mapping.
return attributes;
}
public void setAttributes(Object [] objArray)
{
attributes = objArray;
}
public void setSQLTypeName(String name)
{
typeName = name;
}
}
下列 Java 程序插入一 ROW 列:
PreparedStatement pstmt;
ResultSet rs;
GenericStruct gs;
String rowType;
pstmt = conn.prepareStatement("insert into teachers values (?, 'Math')");
System.out.println("prepare insert...ok\n");
System.out.println("Populate name struct...");
Object[] name = new Object[2];
// populate inner row first
name[0] = new String("Jane");
name[1] = new String("Smith");
rowType = "row(first char(20), last char(20))";
gs = new GenericStruct(rowType, name);
System.out.println("Instantiate GenericStructObject...okay\n");
System.out.println("Populate person struct...");
// populate outer row next
Object[] person = new Object[3];
person[0] = new Integer(99);
person[1] = gs;
person[2] = new Integer(56);
rowType = "row(id int, " +
"name row(first char(20), last char(20)), " +
"age int)";
gs = new GenericStruct(rowType, person);
System.out.println("Instantiate GenericStructObject...okay\n");
pstmt.setObject(1, gs);
System.out.println("setObject()...okay");
pstmt.executeUpdate();
System.out.println("executeUpdate()...okay");
pstmt.close();
在此示例中的 pstmt.setObject(1, gs) 语句处,GBase 8s JDBC Driver 确定要从客户机传至数据库服务器的信息作为 ROW 列,因为GenericStruct 对象是 java.sql.Struct 接口的一个实例。
序列化数组中的每一元素,核实每一元素与由 getSQLTypeName() 方法定义的类型相匹配。
ClassGenerator 实用程序
对于在系统目录中定义的命名的行类型,ClassGenerator 实用程序生成 Java™ 类。该实用程序是对 JDBC 规范的 GBase 8s 扩展。
创建了的 Java 类实现 java.sql.SQLData 接口。对于命名的行中每一字段,该类都有成员。按照出现在数据库中命名的行类型定义中的顺序,readSQL()、writeSQL() 和 SQLData.readSQL() 方法读取属性。类似地,writeSQL() 按该顺序将数据写至流。
将 ClassGenerator 打包在 gbasedbtjdbc_xx.jar 文件中,因此,CLASSPATH 环境变量必须指向 gbasedbtjdbc_xx.jar。
使用 ClassGenerator 的语法如下:
java ClassGenerator rowtypename [-u URL] [-c classname]
classname 的缺省值是 rowtypename 的值。
如果未指定 URL 参数,则从 home 目录中的 setup.std 文件检索所需的信息。
setup.std 的结构如下:
URL jdbc:host-name:port-number
gbasedbtserver gbasedbtservername
database database
user user
passwd password
简单命名的行示例
要使用 ClassGenerator,请首先在数据库服务器上创建命名的行,如此示例中所示:
create row type employee (name char (20), age int);
接下来,运行 ClassGenerator:
java ClassGenerator employee
该类生成器生成 employee.java,如后所示,并从 setup.std 检索数据库 URL 信息,其有下列内容:
URL jdbc:davinci:1528
database test
user scott
passwd tiger
gbasedbtserver picasso_ius
下列为生成了的 .java 文件:
import java.sql.*;
import java.math.*;
public class employee implements SQLData
{
public String name;
public int age;
private String sql_type;
public String getSQLTypeName() { return "employee"; }
public void readSQL (SQLInput stream, String type) throws
SQLException
{
sql_type = type;
name = stream.readString();
age = stream.readInt();
}
public void writeSQL (SQLOutput stream) throws SQLException
{
stream.writeString(name);
stream.writeInt(age);
}
}
嵌套的命名的行示例
对于嵌套的行,要使用 ClassGenerator,请首先在数据库服务器上创建命名的行:
create row type manager (emp employee, salary int);
接下来,运行 ClassGenerator。在此情况下,不查询 setup.std 文件,因为您在命令行提供了所有需要的信息:
java ClassGenerator manager -c Manager -u "jdbc:davinci:1528/test:user=scott;
password=tiger;gbasedbtserver=picasso_ius"
-c 选项定义您正在创建的 Java™ 类,其为 Manager(带有大写的 M)。
前面的命令生成下列 Java 类:
import java.sql.*;
import java.math.*;
public class Manager implements SQLData
{
public employee emp;
public int salary;
private String sql_type;
public String getSQLTypeName() { return "manager"; }
public void readSQL (SQLInput stream, String type) throws
SQLException
{
sql_type = type;
emp = (employee)stream.readObject();
salary = stream.readInt();
}
public void writeSQL (SQLOutput stream) throws SQLException
{
stream.writeObject(emp);
stream.writeInt(salary);
}
}
类型高速缓存信息
当将某些数据类型的对象插入至某些其他数据类型的列内时,GBase 8s JDBC Driver 通过调用 SQLData.getSQLTypeName() 方法,来核实提供的数据与数据库服务器期望的数据是否相匹配。驱动程序询问数据库服务器随同每一插入的类型信息。
这会在下列情况下发生:
- 当 SQLData 对象将输入插入至 opaque 类型列,且 getSQLTypeName() 返回该 opaque 类型的名称时
- 当 Struct 或 SQLData 对象将数据插入至行列,且 getSQLTypeName() 返回命名的行的名称时
- 当 SQLData 对象将数据插入至 DISTINCT 类型列时。
在数据库 URL 中,可设置环境变量 ENABLE_TYPE_CACHE=TRUE,以使得在首次检索时驱动程序高速缓存该数据类型信息。然后,在从数据库服务器请求数据之前,驱动程序向高速缓存请求该类型信息。
智能大对象数据类型
智能大对象是带有下列特性的大对象:
-
智能大对象可保存非常大量的数据。
当前,单个智能大对象可保存最多 4 TB 数据。此数据存储在称为 sbspace 的独立磁盘空间中。
-
智能大对象是可恢复的。
数据库服务器可将更改日志记录至智能大对象,因此,在系统或硬件故障时可恢复智能大对象数据。智能大对象的日志记录不是缺省的行为。
-
智能大对象支持对其数据的随机访问。
以“全部或者全不”方式访问简单大对象(BYTE 或 TEXT);也就是说,数据库服务器一次返回您请求的所有简单大对象数据。对于智能大对象,可寻找所需的位置,并读或写所需的字节数。
-
可定制智能大对象的存储特征。
当创建智能大对象时,可指定智能大对象的存储特征,诸如:
- 数据库服务器是否根据当前数据库日志模式来日志记录智能大对象
- 数据库服务器是否保存最后一次访问智能大对象的痕迹
- 数据库服务器是否使用页标头来检测数据损坏与否
在数据库中作为 BLOB 和 CLOB 数据类型来存储智能大对象,您可以两种方式访问它们:
- 在 GBase 8s JDBC Driver 3.0 和后来版本中,以及支持支持智能大对象数据类型的 GBase 8s 服务器中,可使用 JDBC 3.0 规范中描述的标准 JDBC API 方法。这是较简单的方法。
已实现了对于 BLOG 和 CLOB 内部更新的下列 JDBC 3.0 方法:
int setBytes(long, byte[]) throws SQLException
void truncate(long) throws SQLException
在 GBase 8s JDBC Driver Version 3.0 或后来版本中实现来自 BLOB 接口的下列 JDBC 3.0 方法:
OutputStream setBinaryStream(long) throws SQLException
int setBytes(long, byte[], int, int) throws SQLException
在 GBase 8s JDBC Driver Version 3.0 或后来版本中,实现来自 CLOB 接口的下列 JDBC 3.0 方法:
OutputStream setAsciiStream(long) throws SQLException Writer setCharacterStream(long) throws SQLException
int setString(long, String) throws SQLException
int setString(long, String, int, int) throws SQLException
- 可使用 GBase 8s 内基于智能大对象支持的 GBase 8s 扩展。此方法提供更多选项。
数据库服务器中的智能大对象
在 GBase 8s 数据库服务器中,智能大对象有两个部分:
- 数据,其存储在一个 sbspace 中
- 大对象句柄,称为 LO 句柄,其标识智能大对象数据在 sbspace 中的位置
假定您将员工的照片作为智能大对象存储。下图展示 LO 句柄如何包含关于在 sbspace1_100 sbspace 中实际员工照片的位置信息。
图: 数据库服务器中的智能大对象

在图中,sbspace 保存 LO 句柄标识的实际员工照片。要获取关于 sbspace 的结构,以及关于创建和删除 sbspace 的 onspaces 数据库实用程序的更多信息,请参阅《GBase 8s 管理员指南》。
仅可在 sbspace 中存储智能大对象。在尝试将智能大对象插入至数据库之前,必须创建 sbspace。
由于智能大对象可能非常大,因此,数据库服务器仅在数据库表中存储它的 LO 句柄;然后,它可使用此句柄来找到 sbspace 中智能大对象的实际数据。这种安排最小化表大小。
应用程序从数据库取得 LO 句柄,并使用它来定位智能大对象数据,再打开智能大对象进行读写操作。
客户机应用程序中的智能大对象
在客户机上,JDBC 应用程序可使用 ResultSet 方法来访问智能大对象数据,诸如:
- 对于 CLOB 数据,getClob() 和 getAsciiStream()
- 对于 BLOB 数据,getBlob() 和 getBinaryStream()
- 对于 CLOB 和 BLOB 数据,getString()
在客户机侧,JDBC 驱动程序通过 IfxLocator 对象来引用 LO 句柄。JDBC 应用程序取得 IfxLocator 类的一个实例,来取得智能大对象定位器句柄,如下图所示。应用程序独立地创建智能大对象,然后,将智能大对象插入至不同的列,设置是在多表中。使用多线程,应用程序可并行地从智能大对象的不同部分写或读数据,这非常高效。
图: 在客户机应用程序中定位智能大对象

创建智能大对象
基于下列类实现 GBase 8s 智能大对象:
- IfxLobDescriptor存储大对象的属性。
- IfxLocator 包含至数据库服务器中大对象的句柄。
- IfxSmartBlob包含操作智能大对象的方法,诸如在对象内定位、从对象读取数据,以及将数据写至对象。
- IfxBblob 和 IfxCblob实现来自 JDBC 3.0 规范的 java.sql.Blob 和java.sql.Clob 接口。
- IfxLoStat 存储关于大对象的状态信息。
本部分描述如何使用 GBase 8s 智能大对象接口,但目前它未记录该接口中的每个方法和参数。要获取该接口中所有方法及其参数的完整参考,请参阅 GBase 8s JDBC Driver 的 javadoc 文件,其位于安装驱动程序处的 doc/javadoc 目录中。
要创建智能大对象:
-
对于新的智能大对象,请确保该智能大对象有为其数据指定的一个 sbspace。
要获取关于创建 sbspace 的 onspaces 实用程序的详尽资料,请参阅《GBase 8s 管理员指南》。要获取创建 sbspace 的示例,请参阅 设置 sbspace 特征的示例。
-
创建 IfxLobDescriptor 对象。
这允许您设置智能大对象的存储特征。当 IfxSmartBlob.IfxLoCreate() 方法创建大对象时,驱动程序将 IfxLobDescriptor 对象传至数据库服务器。
-
如果需要,请调用 IfxLobDescriptor 对象中的方法,来指定存储特征。
对于大多数智能大对象,sbspace 名称是您需要指定的唯一存储特征。数据库服务器可计算所有其他存储特征的值。可设置特殊的存储特征,来覆盖这些计算的值。然而,大多数应用程序不需要在此详细级别设置存储特征。要获取更多信息,请参阅 使用存储特征。
-
创建 IfxLocator 对象。
这是至客户机上智能大对象的指针。
-
创建 IfxSmartBlob 对象。
这允许您对智能大对象执行各种通用操作。
-
执行 IfxSmartBlob.IfxLoCreate() 方法,来在数据库服务器中创建大对象。
IfxLoCreate() 采用 IfxLocator 和 IfxLobDescriptor 对象作为参数,来表示数据库服务器中的智能大对象。
-
执行 IfxSmartBlob.IfxLoWrite(),来将数据写至数据库服务器中的智能大对象。
-
执行附加的 IfxSmartBlob 方法,来在对象内定位、从对象读取,等等。
-
执行 IfxSmartBlob.IfxLoClose(),来关闭大对象。
-
将智能大对象插入至数据库内(请参阅 将智能大对象插入至列内)。
-
执行 IfxSmartBlob.IfxLoRelease(),来释放定位器指针。
创建 IfxLobDescriptor 对象
IfxLobDescriptor 类存储智能大对象的内部存储特征。在数据库服务器上可创建智能大对象之前,您必须创建一 IfxLobDescriptor 对象,如下:
IfxLobDescriptor loDesc = new IfxLobDescriptor(conn);
conn 参数是 java.sql.Connection 对象。IfxLobDescriptor() 构造函数为该对象设置所有缺省值。
要获取关于内部存储特征的更多信息,请参阅 使用存储特征。
创建 IfxLocator 对象
IfxLocator 对象(通常称为定位器指针或大对象定位器)表示智能大对象的位置,如 图 1 中所示;对于特殊的大对象,定位器指针是在数据库服务器与客户机之间的通讯链接。在它创建大对象或打开大对象进行读写之前,应用程序必须创建一 IfxLocator 对象:
IfxLocator loPtr = new IfxLocator();
IfxLocator loPtr = new IfxLocator(Connection conn);
如果抛出异常,则使用这些构造函数的第二个来显示本地化的错误消息。要获取更多信息,请参阅 支持全球化的错误消息。
创建 IfxSmartBlob 对象
要创建智能大对象,并取得对方法的访问,以对该对象执行操作,请调用 IfxSmartBlob 构造函数,将引用传至 JDBC 连接:
IfxSmartBlob smb = new IfxSmartBlob(myConn)
一旦编写了需要在智能大对象中执行操作的所有方法,您即可使用 IfxSmartBlob.IfxLoCreate() 方法,来在数据库服务器中创建大对象,并打开它来在应用程序内访问。该方法签名如下:
public int IfxLoCreate(IfxLobDescriptor loDesc, int flag,
IfxLocator loPtr) throws SQLException
public int IfxLoCreate(IfxLobDescriptor loDesc, int flag,
IfxBblob blob)throws SQLException
public int IfxLoCreate(IfxLobDescriptor loDesc, int flag,
IfxCblob clob throws SQLException
返回值是定位器句柄,您可在后续的读、写、搜索和关闭方法中使用它(您可将它作为定位器文件描述符(lofd)参数,将它传至操作打开的智能大对象方法;在 智能大对象内的位置 的开始描述这些方法)。
flag 参数是一整数值,指定在服务器中打开新的智能大对象所处的访问模式。对打开的智能大对象,访问模式确定哪些读写操作是有效的。如果未指定值,则以只读模式打开该对象。
请在下表中以 IfxLoCreate() 和 IfxLoOpen() 方法,来使用访问模式 flag 值,以特定的访问模式打开或创建智能大对象。
| 访问模式 | 用途 | IfxSmartBlob 中的 flag 值 |
|---|---|---|
| Read only | 仅允许读操作 | LO_RDONLY |
| Write only | 仅允许写操作 | LO_WRONLY |
| Write/Append | 将写的数据追加至智能大对象的末尾。单独使用时,它等同于 write-only 模式,后跟一个至智能大对象末尾的搜索。读操作失败。当仅以 write/append 模式打开智能大对象时,以 write-only 模式打开该智能大对象。搜索操作移动搜索位置,但对智能大对象的读操作失败,且搜索位置保持不变,与写之前的位置一样。在搜索位置发生写操作,然后移动该搜索位置。 | LO_APPEND |
| Read/Write | 允许读和写操作。 | LO_RDWR |
下列示例展示如何使用 LO_RDWR flag 值:
IfxSmartBlob smb = new IfxSmartBlob(myConn);
int loFd = smb.IfxLoCreate(loDesc, smb.LO_RDWR, loPtr);
预先创建 loDesc 和 loPtr 对象,分别为 IfxLobDescriptor 和 IfxLocator 对象。
当打开智能大对象时,数据库服务器使用下列系统缺省值。
打开模式信息
缺省的打开模式
访问模式
Read-only
访问方法
Random
缓冲
Buffered access
锁定
Whole-object locks
要获取关于锁定的更多信息,请参阅 使用锁。
下表提供打开模式标志的全集:
| 打开模式标志 | 描述 |
|---|---|
| LO_APPEND | 将写的数据追加至智能大对象的末尾 单独使用时,它等同于 write-only 模式,后跟至智能大对象末尾的搜索。读操作失败。 当仅以 write/append 模式打开智能大对象时,以 write-only 模式打开智能大对象。搜索操作移动搜索位置,但对智能大对象的读操作失败,且搜索位置保持不变,与写之前的位置一样。在搜索位置处发生写操作,然后,移动搜索位置。 |
| LO_WRONLY | 仅允许写操作 |
| LO_RDONLY | 仅允许读操作 |
| LO_RDWR | 允许写和读操作 |
| LO_DIRTY_READ | 仅对于打开 允许读取智能大对象的未提交的数据页 在设置模式为 LO_DIRTY_READ 之后,不可写至智能大对象。当设置此标志时,对于智能大对象,请将当前的事务隔离模式重置为 Dirty Read。 在 Dirty Read 模式下,请不要对从智能大对象取得的数据进行基础更新。 |
| LO_RANDOM | 覆盖优化器决策 指示随意 I/O,且数据库服务器不应预读。缺省的打开模式。 |
| LO_SEQUENTIAL | 覆盖优化器决策 指示读为前向或反向顺序的。 |
| LO_FORWARD | 仅用于顺序访问,来指示前向 |
| LO_REVERSE | 仅用于顺序访问,来指示反向 |
| LO_BUFFER | 使用数据库服务器缓冲池。 |
| LO_NOBUFFER | 不使用标准数据库服务器缓冲池。使用来自数据库服务器的会话池的私有缓冲区。 |
| LO_NODIRTY_READ | 不允许对智能大对象进行脏读。要获取更多信息,请参阅 LO_DIRTY_READ 标志。 |
| LO_LOCKALL | 指定会在整个智能大对象上发生锁定 |
| LO_LOCKRANGE | 对于字节的范围,指定会发生锁定 当放置锁时,请通过 IfxSmartBlob.IfxLoLock() 方法来指定字节的范围。 |
将智能大对象插入至列内
在创建智能大对象之后,您必须将它插入至 BLOB 或 CLOB 列,以将它保存在数据库中。要这么做,您必须将 IfxLocator 对象转换为 IfxBblob 或IfxCblob 对象,这依赖于列类型。
要将智能大对象插入至 BLOB 或 CLOB 列,请:
-
创建 IfxBblob 或 IfxCblob 对象,如下:
IfxBblob blb = new IfxBblob(loPtr);loPtr 参数是从前面的步骤取得的集合中的一个 IfxLocator 对象。
-
使用 PreparedStatement.setBlob() 或 setClob() 方法,来将该对象插入至列内。
在插入执行之前,在数据库服务器中必须存在智能大对象的 sbspace。
访问智能大对象
遵循下列步骤来使用 GBase 8s 扩展,以从数据库列选择智能大对象。
要访问智能大对象,请:
- 将 java.sql.Blob 或 java.sql.Clob 对象强制转型为 IfxBblob 或 IfxCblob 对象。
- 使用 IfxBblob.getLocator() 或 IfxCblob.getLocator() 方法,来抽取 IfxLocator 对象。
- 创建 IfxSmartBlob 对象。
- 使用 IfxSmartBlob.IfxLoOpen() 方法,来打开智能大对象。
- 使用 IfxSmartBlob.IfxLoRead() 方法来从智能大对象读取数据。
- 使用 IfxSmartBlob.IfxLoClose() 方法来关闭智能大对象。
- 通过调用 IfxSmartBlob.IfxLoRelease() 方法,来释放服务器中的定位器指针。
标准 JDBC ResultSet 方法,诸如 ResultSet.getBinaryStream()、getAsciiStream()、getString()、getBytes()、getBlob() 和 getClob(),可从表访存 BLOB 或 CLOB 数据。然后, GBase 8s 扩展类可访问该数据。
在智能大对象上执行操作
在数据库服务器中,在有下列数据类型之一的列中,可直接存储智能大对象:
- CLOB 数据类型保存文本数据。
- BLOB 数据类型可在不可分的字节流中存储任何类别的二进制数据。
CLOB 或 BLOB 列为智能大对象保存 LO 句柄。因此,当选择 CLOB 或 BLOB 列时,不取得智能大对象的实际数据,而是标识此数据的 LO 句柄。智能大对象的列有理论上的 4 TB 限制,并由磁盘容量确定实际的限制。
可使用下列方式之一来在列中存储智能大对象:
- 对于智能大对象的直接访问,创建 CLOB 或 BLOB 数据类型的列。
- 要在原子数据类型内隐藏智能大对象,创建保存智能大对象的 opaque 类型。
在客户机应用程序中,IfxBblob 和 IfxCblob 类是在 JDBC 3.0 规范中描述的处理智能大对象数据方式与 GBase 8s 扩展之间的桥梁。IfxBblob 类实现 java.sql.Blob 接口,IfxCblob 类实现 java.sql.Clob 接口。 GBase 8s 扩展需要一个 IfxLocator 对象,来标识数据库服务器中的智能大对象。
当查询包含 BLOB 或 CLOB 类型列的表时,返回一个 Blob 或 Clob 类型的对象,这依赖于列类型。然后,可使用 Blob 或 Clob 类型对象的 JDBC 3.0 支持函数,来访问智能大对象。
构造函数从 IfxLocator 对象 loPtr 创建一个 IfxBblob 或 IfxCblob 对象:
public IfxBblob(IfxLocator loPtr)
public IfxCblob(IfxLocator loPtr)
下列定位器方法从 IfxBblob 或 IfxCblob 对象返回一个 IfxLocator 对象。然后,您可使用 IfxSmartBlob.IfxLoOpen()、IfxLoRead() 和IfxLoWrite() 方法,来打开、读和写智能大对象:
public IfxLocator getLocator() throws SQLException
打开智能大对象
IfxSmartBlob 类中的下列方法打开数据库服务器中现有的智能大对象:
public int IfxLoOpen(IfxLocator loPtr, int flag) throws
SQLException
public int IfxLoOpen(IfxBblob blob, int flag) throws SQLException
public int IfxLoOpen(IfxCblob clob, int flag) throws SQLException
第一个版本打开由定位器指针 loPtr 引用的智能大对象。第二个和第三个版本分别打开由指定的 IfxBblob 和 IfxCblob 对象引用的智能大对象。flag参数是来自 创建 IfxSmartBlob 对象 中表的一个值。
智能大对象内的位置
IfxSmartBlob 类中的 IfxLoTell() 方法返回当前的查找位置,其为智能大对象下一读或写操作的偏移量。IfxSmartBlob 类中的 IfxLoSeek() 方法设置已打开的大对象内的读或写位置。
public long IfxLoTell(int lofd)
public long IfxLoSeek(int lofd, long offset, int whence) throws
SQLException
绝对位置依赖于第二个参数 offset 的值和第三个参数 whence 的值。
lofd 参数是由 IfxLoCreate() 或 IfxLoOpen() 方法返回的定位符文件描述符。offset 参数是从开始的查找位置的偏移量。
whence 参数标识开始查找位置。请使用下表中的 whence 值来定义智能大对象内的位置,来启动查找操作。
| 开始的查找位置 | whence 值 |
|---|---|
| 智能大对象的开头 | IfxSmartBlob.LO_SEEK_SET |
| 智能大对象中的当前位置 | IfxSmartBlob.LO_SEEK_CUR |
| 智能大对象的结束 | IfxSmartBlob.LO_SEEK_END |
返回值是表示智能大对象内绝对位置的长整数。
下列示例展示如何使用 LO_SEEK_SET whence 值:
IfxLobDescriptor loDesc = new IfxLobDescriptor(myConn);
IfxLocator loPtr = new IfxLocator();
IfxSmartBlob smb = new IfxSmartBlob(myConn);
int loFd = smb.IfxLoCreate(loDesc, smb.LO_RDWR, loPtr);
int n = smb.IfxLoWrite(loFd, fin, fileLength);
smb.IfxLoClose(loFd);
loFd = smb.IfxLoOpen(loPtr, smb.LO_RDWR);
long m = smb.IfxLoSeek(loFd, 200, smb.LO_SEEK_SET);
将写位置设置在从智能大对象开头的 200 字节偏移量处。
从智能大对象读取数据
可以下列方式从智能大对象读取数据:
- 将数据从对象读取至 byte[ ] 缓冲区内。
- 将数据从对象读取至文件输出流内。
- 将数据从对象读取至文件内。
请使用 IfxSmartBlob 类中的 IfxLoRead() 方法来从智能大对象读取至缓冲区内或文件输出流内,其有下列签名:
public byte[] IfxLoRead(int lofd, int nbytes) throws SQLException
public int IfxLoRead(int lofd, byte[] buffer, int nbytes) throws
SQLException
public int IfxLoRead(int lofd, FileOutputStream fout, int nbytes
throws SQLException
public int IfxLoRead(int lofd, byte[] buffer, int nbytes, int
offset throws SQLException
lofd 参数是由 IfxLoRead() 或 IfxLoOpen() 方法返回的定位器文件描述符。
第一个版本将 nbytes 字节数据返回至字节缓冲区内。此版本的方法为缓冲区分配内存。第二个版本将 nbytes 字节数据读至已分配了的缓冲区内。第三个版本将 nbytes 字节数据读至文件输出流内。第四个版本将 nbytes 字节数据读至在当前查找位置加上智能大对象内偏移量处开始的字节缓冲区内。最后三个版本的返回值指示读取的字节数。
使用 IfxSmartBlob 类中的 IfxLoToFile() 方法,来从智能大对象读取至文件内,其有下列签名:
public int IfxLoToFile(IfxLocator loPtr, String filename, int flag , int whence) throws SQLException
public int IfxLoToFile(IfxBblob blob, String filename, int flag , int whence) throws SQLException
public int IfxLoToFile(IfxCblob clob, String filename, int flag , int whence) throws SQLException
第一个版本读取由定位器指针 loPtr 引用的智能大对象。第二个和第三个版本分别读取由指定的 IfxBblob 和 IfxCblob 对象引用的智能大对象。
flag 参数指示该文件是在客户机上,还是在服务器上。该值为 IfxSmartBlob.LO_CLIENT_FILE 或 IfxSmartBlob.LO_SERVER_FILE。whence 参数指示开始的查找位置。要了解这些值,请参阅 智能大对象内的位置。
在下列函数的签名中,已有一更改:
IfxSmartBlob.IfxLoToFile().
此函数用于接受四个参数,但现在仅接受三个参数。IfxLoToFile() 的所有三个重载的函数都接受三个参数。
将数据写至智能大对象
可以下列方式将数据写至智能大对象:
- 将数据从 byte[ ] 缓冲区写至该对象。
- 将数据从文件输入流写至该对象。
- 将数据从文件写至该对象。
使用 IfxSmartBlob 类中的 IfxLoWrite() 方法,从 byte[ ] 缓冲区或文件输入流写至智能大对象:
public int IfxLoWrite(int lofd, byte[] buffer) throws SQLException
public int IfxLoWrite(int lofd, InputStream fin, int length) throws SQLException
该方法的第一个版本将 buffer.length 字节数据从缓冲区写至智能大对象内。第二个版本将 length 字节数据从 InputStream 对象写至智能大对象内。
lofd 参数是由 IfxLoCreate() 或 IfxLoOpen() 方法返回的定位器文件描述符。buffer 参数是读数据处的 byte[] 缓冲区。fin 是 InputStream 对象,将数据从其写至智能大对象内。length 参数是写至智能大对象内的字节数。驱动程序返回写入的字节数。
请使用 IfxSmartBlob 类中的 IfxLoFromFile() 方法,来将数据从文件写至智能大对象:
public int IfxLoFromFile (int lofd, String filename, int flag, int offset, int amount) throws SQLException
lofd 参数是由 IfxLoCreate() 或 IfxLoOpen() 方法返回的定位器文件描述符。flag 参数指示该文件是在客户机上,还是在服务器上。该值为IfxSmartBlob.LO_CLIENT_FILE 或 IfxSmartBlob.LO_SERVER_FILE。
驱动程序返回写入的字节数。
截断智能大对象
请使用 IfxSmartBlob 类中的 IfxLoTruncate() 方法,来在指定的偏移量处截断大对象。该方法签名如下:
public void IfxLoTruncate(int lofd, long offset) throws
SQLException
offset 参数是截断智能大对象处的绝对位置。
度量智能大对象
请使用 IfxSmartBlob 类中的 IfxLoSize() 方法,来返回智能大对象的大小。此方法返回表示大对象大小的一个长整数。
该方法签名如下:
public long IfxLoSize(int lofd) throws SQLException
关闭和释放智能大对象
在执行了应用程序需要的所有操作之后,您必须关闭该对象,然后,释放服务器中的资源。执行这些任务的 IfxSmartBlob 类中的方法如下:
public void IfxLoClose(int lofd) throws SQLException
public void IfxLoRelease(IfxLocator loPtr) throws SQLException
public void IfxLoRelease(IfxBblob blob) throws SQLException
public void IfxLoRelease(IfxCblob clob) throws SQLException
要对同一大对象进行任何进一步访问,必须以 IfxLoOpen() 方法来重新打开它。
将 IfxLocator 转换为十六进制字符串
有些应用程序只能处理 ASCII 数据,例如,web 浏览器;它们需要将 IfxLocator 转换为十六进制字符串格式。在典型的基于 web 的应用程序中,web 服务器查询数据库表,并将结果发送至浏览器。不是发送整个智能大对象,web 服务器将定位器转换为十六进制字符串格式,并将它发送至浏览器。如果用户请求浏览器显示智能大对象,则浏览器将十六进制格式的定位器发回 web 服务器。然后,web 服务器从该十六进制字符串重构二进制定位器,并将对应的智能大对象数据发送至浏览器。
要在 IfxLocator 字节数组与十六进制数值之间转换,请使用罗列在下表中的方法。
| 执行的任务 | 方法签名 | 附加的信息 |
|---|---|---|
| 将字节数组转换为十六进制字符串 | public static String toHexString( byte[] byteBuf); | 对数据有效,而不是对在com.gbasedbt.util.stringUtil 类中提供的 IfxLocator |
| 将十六进制字符串转换为字节数组 | public static byte[] fromHexString( String str) throws NumberFormatException; | 对数据有效,而不是对com.gbasedbt.util.stringUtil 类中提供的 IfxLocator |
| 使用字节数组构造一个 IfxLocator 对象 | public IfxLocator(byte[] byteBuf) throws SQLException; | 在 IfxLocator 类中提供 |
| 将 IfxLocator 字节数组转换为十六进制字符串 | public String toString(); | 在 IfxLocator 类中提供 |
| 将十六进制字符串转换为 IfxLocator 字节数组 | public byte[] toBytes(); | 在 IfxLocator 类中提供 |
下列示例使用 toString() 和 toBytes() 方法,来从智能大对象访存定位器,然后,将它转换为十六进制字符串:
...
String hexLoc = "";
byte[] blobBytes;
byte[] rawLocA = null;
IfxLocator loc;
try
{
ResultSet rs = stmt.executeQuery("select b1 from btab");
while(rs.next())
{
IfxBblob b=(IfxBblob)rs.getBlob(1);
loc =b.getLocator();
hexLoc = loc.toString();
rawLocA = loc.toBytes();
}
}
catch(SQLException e)
{}
下列示例使用 IfxLocator() 方法来构建 IfxLocator,然后使用其来读取智能大对象:
...
try
{
IfxLocator loc2 = new IfxLocator(rawLoc);
IfxSmartBlob b2 = new IfxSmartBlob((IfxConnection)myConn);
int lofd = b2.IfxLoOpen(loc2, b2.LO_RDWR);
blobBytes = b2.IfxLoRead(lofd, fileLength);
}
catch(SQLException e)
{}
使用存储特征
存储特征告诉数据库服务器如何管理智能大对象。这些特征包括诸如大小、日志记录、锁定和打开模式这样的领域。关于存储特征,有下列选项:
- 使用特定于系统的存储特征作为取得智能大对象的存储特征的基础。
- 以下列之一来覆盖系统缺省值:
- 为您想要在其中存储智能大对象的特别 CLOB 或 BLOB 列定义的存储特征
- 特别 CLOB 或 BLOB 列特有的存储特征,称为列级存储特征
- 仅为此智能大对象定义的特殊存储特征,称为特定于用户的存储特征
数据库服务器使用层级结构来从新的智能大对象取得存储特征,如下图所示。
图: 存储特征层级结构
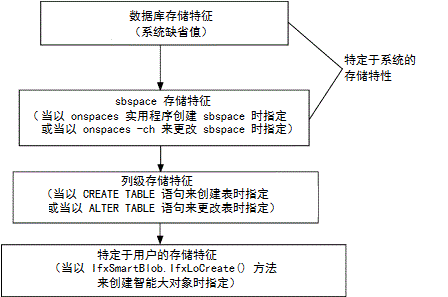
对于给定的存储特征,在列级定义的任何值都覆盖特定于系统的值,任何用户级的值都覆盖列级的值。可在下表中展示的三个时刻指定存储特征。
| 何时指定 | 如何指定 | 要获取更多信息 |
|---|---|---|
| 当创建 sbspace 时 | onspaces 实用程序的选项 | 特定于系统的存储特征 GBase 8s 管理员指南 |
| 当创建数据库表时 | CREATE TABLE 语句的 PUT 子句中的关键字 | GBase 8s SQL 指南:语法 |
| 当创建智能大对象时 | 在 ifxLobDescriptor 类中创建标志和方法 | 设置创建标志 |
特定于系统的存储特征
当数据库管理员初始化数据库服务器并以 onspaces 实用程序创建 sbspace 时,建立特定于系统的存储特征,如下:
- 如果 onspaces 实用程序已为特定的存储特征指定了值,则数据库服务器使用 onspaces 值作为特定于系统的存储特征。
- 如果 onspaces 实用程序还未为特定的存储特征指定值,则数据库服务器使用系统缺省值作为特定于系统的存储特征。
特定于系统的存储特征适用于存储在 sbspace 中的所有智能大对象,除非智能大对象以列级或特定于用户的存储特征特意覆盖它们。
要了解 onspaces 可设置的存储特征,以及系统缺省值,请参阅 表 1 。
对于大多数应用程序,推荐您使用存储特征的特定于系统的缺省值。请注意下列例外:
-
应用程序需要取得额外的性能。
可使用 ifxLobDescriptor 中的 setXXX() 方法,来更改新智能大对象的磁盘存储信息。要获取更多信息,请参阅 设置创建标志。
-
想要使用现有智能大对象的存储特征。
IfxLoStat.getLobDescriptor() 方法可取得打开的智能大对象的大对象描述符。然后,可创建新的对象,并使用IfxSmartBlob.ifxLoAlter() 方法来将它的特征设置为新的描述符。要获取更多信息,请参阅 更改存储特征。
-
正在使用多个智能大对象,且不想使用缺省的 sbspace。
DBA 可以 onconfig 文件中的 SBSPACENAME 配置参数来指定缺省的 sbspace 名称。然而,必须确保您创建的智能大对象位置(sbspace 的名称)是正确的。如果未为您的智能大对象指定 sbspace 名称,则数据库服务器将它存储在此缺省的 sbspace 中。此安排可导致空间限制。
-
如果知道智能大对象的大小,请使用 IfxLobDescriptor.setEstBytes() 方法来在应用程序中指定此大小,而不使用 onspaces 实用程序(系统级)或 CREATE TABLE 或 ALTER TABLE 语句(列级)。
取得关于存储特征的信息
要获取智能大对象的列级存储特征,应用程序可调用 IfxSmartBlob 类中的下列方法,传递 colname 参数的列名称:
IfxLobDescriptor IfxLoColInfo(java.lang.String colname) throws
SQLException
大多数应用程序仅需要确保 sbspace 名称的正确存储特征(智能大对象的位置)。在创建 IfxSmartBlob 对象之前,通过调用 ifxLobDescriptor 类中的各种 getXXX() 方法,可取得此存储特征和其他存储特征的信息。下表总结 getXXX() 方法。
| ifxLobDescriptor 中的方法签名 | 用途 |
|---|---|
| int getCreateFlags() | 取得对象的创建标志 |
| long getEstSize() | 取得对象的估算大小,以字节计 |
| int getExtSize() | 取得对象的 extent 大小 |
| long getMaxBytes() | 取得对象的最大大小,以字节计 |
| java.lang.String getSbspace() | 取得对象存储在其中的数据库服务器中的 sbspace 名称 |
设置 sbspace 特征的示例
下列对 onspaces 实用程序的调用在 /dev/sbspace1 分区中创建名为 sb1 的 sbspace:
onspaces -c -S sb1 -p /dev/sbspace1 -o 500 -s 2000
-Df "AVG_LO_SIZE=32"
对于 sb1 sbspace 中的所有智能大对象,下表展示结果的特定于系统的存储特征。
表 1. sb1 sbspace 的特定于系统的存储特征
| 磁盘存储信息 | 特定于系统的值 | 由 onspaces 实用程序指定 |
|---|---|---|
| extent 的大小 | 由数据库服务器计算 | 系统缺省值 |
| 下一 extent 的大小 | 由数据库服务器计算 | 系统缺省值 |
| 最小 extent 大小 | 由数据库服务器计算 | 系统缺省值 |
| 智能大对象的大小 | 32 KB(数据库服务器用作大小估算) | AVG_LO_SIZE |
| I/O 块的最大大小 | 由数据库服务器计算 | 系统缺省值 |
| sbspace 的名称 | sb1 | -S 选项 |
| 日志记录 | OFF | 系统缺省值 |
| 最后访问时间 | OFF | 系统缺省值 |
使用磁盘存储信息
磁盘存储信息帮助数据库服务器确定如何最高效地管理磁盘上的智能大对象。
对于大多数应用程序,使用数据库服务器为磁盘存储信息计算的值。GBase 8s JDBC Driver 中提供的方法用作特殊情况。
此磁盘存储信息包括:
-
extent 分配信息:
- extent 大小:
分配 extent是数据库服务器一次分配给智能大对象的 sbspace 内连续字节的集合。数据库服务器以 extent 大小的增量为智能大对象执行存储分配。
通过调用 ifxLobDescriptor.setExtSize() 方法可指定 extent 大小。
- 下一 extent 大小:
数据库服务器试图作为 chunk 中单个连续的区域来分配 extent。然而,如果没有足够大的单个 extent ,则数据库服务器必须使用所需的多个 extent 来满足当前的写请求。 在初始的 extent 填满之后,数据库服务器尝试分配另一连续的 extent 磁盘空间。此过程称为下一 extent 分配。
要获取关于 extent 的更多信息,请参阅《GBase 8s 管理员指南》中关于磁盘结构和存储的主题。
-
大小信息:
- 新智能大对象中估算的字节数
- 智能大对象可增长到的最大字节数
要指定大小信息,可使用 ifxLobDescriptor 类中的 setMaxBytes() 和 setEstBytes() 方法。
如果知道智能大对象的大小,则请使用 setEstBytes() 方法来指定此大小。这是设置 extent 大小的最佳方式,因为数据库服务器可分配整个智能大对象作为一个 extent。
-
位置:
标识存储智能大对象处位置的 sbspace 名称。要设置此名称,可使用 ifxLobDescriptor.setSbSpace() 方法。
数据库服务器使用磁盘存储信息,来确定如何最优地确定大小、分配和管理 sbspace 的 extent。它可为智能大对象计算除了 sbspace 名称之外的所有磁盘存储信息。
为智能大对象指定磁盘存储信息的方法。通过使用系统缺省值,或由 onspaces 实用程序指定的值来取得特定于系统的磁盘存储信息。由 CREATE TABLE 的 PUT 子句来指定列级存储特征。由 GBase 8s JDBC Driver 方法来指定特定于用户的存储特征。
下表总结为智能大对象指定磁盘存储信息的方式。
表 1. 指定磁盘存储信息.
| 磁盘存储信息 | 特定于系统的存储特征 | 列级存储特征 | 特定于用户的存储特征 | |
|---|---|---|---|---|
| 系统缺省值 | 由 onspaces 实用程序指定 | 由 CREATE TABLE 的 PUT 子句指定 | 由 GBase 8s JDBC Driver 方法指定 | |
| extent 的大小 | 由数据库服务器计算 | EXTENT_SIZE | EXTENT SIZE | 是 |
| 下一 extent 的大小 | 由数据库服务器计算 | NEXT_SIZE | 否 | 否 |
| 最小 extent 大小 | 4 KB | MIN_EXT_SIZE | 否 | 否 |
| 智能大对象的大小 | 由数据库服务器计算 | sbspace 中所有智能大对象的平均大小:AVG_LO_SIZE | 否 | 特殊智能大对象的估计大小,特殊智能大对象的最大大小 |
| I/O 块的最大大小 | 由数据库服务器计算 | MAX_IO_SIZE | 否 | 否 |
| sbspace 的名称 | SBSPACENAME | -S 选项 | 智能大对象在其中的现有 sbspace 名称:IN 子句 | 是 |
使用日志记录、最后访问时间,以及数据完整性
数据库管理员和应用程序可影响某些附加的智能大对象属性:
- 是否在系统日志文件中记录智能大对象的更改
- 是否保存智能大对象的最后访问时间
- 如何格式化智能大对象的 sbspace 中的页
下表总结如何在系统、列和应用程序级别上修改这些属性。
表 1. 指定属性信息
| 属性信息 | 特定于系统的存储特征缺省值 | 特定于系统的存储特征,由 onspaces 实用程序指定 | 列级存储特征,由 CREATE TABLE 的 PUT 子句指定 | 特定于用户的存储特征,由 JDBC 驱动程序方法指定 |
|---|---|---|---|---|
| 日志记录 | OFF | LOGGING | LOG、NO LOG | 是 |
| 最后访问时间 | OFF | ACCESSTIME | KEEP ACCESS TIME、NO KEEP ACCESS TIME | 是 |
| 缓冲模式 | OFF | BUFFERING | 否 | 否 |
| 锁定模式 | 锁定整个智能大对象 | LOCK_MODE | 否 | 是 |
| 数据完整性 | 高完整性 | 否 | HIGH INTEG、MODERATE INTEG | 是 |
日志记录
在缺省情况下,数据库服务器不日志记录智能大对象的用户数据。您可控制智能大对象的日志记录行为,作为它的创建标志的一部分。要获取更多信息,请参阅 设置创建标志。
当数据库执行日志记录时,由于下列原因,智能大对象可能导致长事务:
- 智能大对象非常大,甚至达到数 GB 大小。
日志记录用户数据所需的日志存储量很容易使日志溢出。
- 在数据集合可相当长的情况下,可能使用智能大对象。
例如,如果智能大对象保存低品质音频记录,则数据集合的量可能不太大,但记录的会话可能非常长。
简单的变通方法是将长事务分成几个较小的事务。然而,如果不能接受此情况,则可控制数据库服务器执行智能大对象日志记录的时间。(表 1 展示可如何控制智能大对象的日志记录行为。)
当启用日志记录时,数据库服务器日志记录对智能大对象的用户数据的更改。它按照当前的数据库日志模式来执行此日志记录。
对于不符合 ANSI 的数据库,数据库服务器不保证在事务提交时刷新关于智能大对象的日志记录。然而,元数据总能恢复至活动一致状态;也就是说,恢复至确保在元数据(智能大对象的控制信息,诸如引用计数)中不存在结构性不一致的状态。
符合 ANSI 的数据库服务器使用非缓冲的日志记录。当启用智能大对象日志记录时,在事务提交时,刷新关于智能大对象的所有日志记录(元数据和用户数据)。然而,在提交时刻,不保证将用户数据刷新至它的稳定存储位置。
当禁用日志记录时,即使数据库服务器日志记录其他数据库更改,数据库服务器也不日志记录对用户数据的更改。然而,数据库服务器始终日志记录对元数据的更改。因此,数据库服务器仍可将元数据恢复至活动一致状态。
请慎重考虑是否启用智能大对象的日志记录。数据库服务器会承受对智能大对象的相当高的开销。您还必须确保系统日志文件足够大,以保存智能大对象的值。当更新事务是活动的时,逻辑日志大小必须超过数据库服务器日志记录的数据的总量。
编写应用程序,以便于任何带有潜在长更新的智能大对象的事务不会导致其他事务等待。如果满足下列条件,则多个事务可访问同一智能大对象实例:
- 对于智能大对象,事务可访问包含 LO 句柄的数据库行。
对于同一智能大对象,如果多列持有 LO 句柄,则在同一智能大对象上可存在多个引用。
- 在智能大对象上,另一事务不持有互相冲突的锁。
要获取关于智能大对象锁的更多信息,请参阅 使用锁。
在加载操作完成之后,当加载智能大对象并重新启用它时,当禁用日志记录特性时,会产生最佳更新性能和最少的逻辑日志问题。如果开启日志记录,则在批量加载然后执行 0 级备份之前,您可能想要关闭日志记录。
最后访问时间
智能大对象的最后访问时间是数据库服务器最后读或写智能大对象时的系统时间。最后访问时间记录对智能大对象的用户数据和元数据的访问。以从 1970 年 1 月 1 日以来的秒数来存储此系统时间。数据库服务器在 sbspace 的元数据区域中存储此最后访问时间。
在缺省情况下,数据库服务器不保存最后访问时间。通过设置 LO_KEEP_LASTACCESS_TIME 创建标志并调用 IfxLobDescriptor.setCreateFlags()方法,可指定保存最后访问时间。要获取更多信息,请参阅 设置创建标志。
对于智能大对象,数据库服务器还跟踪最后修改时间和最后状态更改。要获取更多信息,请参阅 使用状态特征。
请慎重考虑是否跟踪智能大对象的最后访问时间。对于智能大对象,日志记录与维护最后访问时间并发,都会使数据库服务器承受相当高的开销。
数据完整性
通过调用 IfxLobDescriptor.setCreateFlags() 方法,以 LO_HIGH_INTEG 和 LO_MODERATE_INTEG 创建标志,可指定数据完整性。要获取更多信息,请参阅 设置创建标志。
sbpage 是为智能大对象数据分配的单元,其存储在 sbspace 的用户数据区域中。sbspace 中 sbpage 的结构确定数据库服务器可提供何种程度的数据完整性。数据库服务器使用页标头和页结尾来检测不完整的写和数据损坏。
数据库服务器支持下列数据完整性级别:
- 高完整性告诉数据库,在每一 sbpage 中同时使用页标头和页结尾。
- 中等完整性告诉数据库服务器,在每一 sbpage 中仅使用页标头。
中等完整性提供下列优势:
- 它排除额外的数据复制操作,当 sbpage 有页标头和页结尾时,这是必需的。
- 它保持页上用户数据对齐,因为不出现页标头和页结尾。
对于包含大量通过数据库服务器移动的音频或视频文件,且不需要高数据完整性的智能大对象,中等完整性可能非常有用。在缺省情况下,数据库服务器使用 sbspace 页的高完整性(页标头和页结尾)。您可控制智能大对象的数据完整性,作为它的存储特征的一部分。
对于智能大对象,请慎重考虑是否使用 sbpage 的中等完整性。虽然中等完整性每页占用较少磁盘空间,但如果发生磁盘错误,它也降低了数据库服务器恢复信息的能力。
要获取关于 sbspace 页的信息,请参阅《GBase 8s 管理员指南》。
更改存储特征
IfxSmartBlob 类中的 IfxLoAlter() 方法允许您更改智能大对象的存储特征。
要更改智能大对象特征,请:
-
创建新的大对象描述符。
例如:
IfxLobDescriptor loDesc = new IfxLobDescriptor(conn); -
调用 IfxLobDescriptor.setCreateFlags()、setEstBytes()、IfxLobDescriptor.setMaxBytes()、setExtSize 和 setSbspace(),来指定新特征:
public void setCreateFlags( int flags )
public void setEstBytes(long estSize)
public void setMaxBytes (long maxSize)
public void setExtSize (long extSize)
public void setSbspace(java.lang.String sbspacename)flag 参数是来自 设置创建标志 的常量。
调用 IfxLoAlter() 来修改现有的智能大对象,以包含该新描述符:
public int IfxLoAlter(IfxLocator loPtr, IfxLobDescriptor loDesc)
hrows SQLException
public int IfxLoAlter(IfxBblob blob, IfxLobDescriptor loDesc)
throws SQLException
public int IfxLoAlter(IfxCblob clob, IfxLobDescriptor loDesc)
throws SQLException
在进行更新之前,对于整个智能大对象,IfxLoAlter() 在服务器中取得一个排他锁。它保持此锁,直至更新完成为止。
设置创建标志
通过调用 IfxLobDescriptor.setCreateFlags() 方法,可更改下列特征:
- 日志记录特征
可指定 LO_LOG 或 LO_ NOLOG 常量。
对于对应的智能大对象,LO_LOG 导致服务器遵循当前数据库日志使用的日志记录过程。此选项可生成大量日志流量,并增加逻辑日志填满的风险。
不采用完全日志记录,当初始地加载智能大对象时,您可以关闭日志记录,然后一旦加载了智能大对象,就再一次开启日志记录。如果使用 NO LOG,则稍后将智能大对象元数据恢复至不存在结构性不一致的状态。在大多数情况下,都不存在事务不一致性,但不能保证该结果。
要获取关于日志记录的更多详细用法信息,请参阅 日志记录。
- 最后访问时间特征
可指定 LO_ KEEP_LASTACCESS_TIME 或 LO NOKEEP_LASTACCESS_TIME 常量。在智能大对象元数据中,LO_ KEEP_LASTACCESS_TIME 记录最后读或写对应的智能大对象时的系统时间。
要获取关于最后访问时间的更详尽用法,请参阅 最后访问时间。
- 是否通过以页标头和页结尾来产生用户数据页,以检测不完整的写和数据损坏
可指定 LO_ HIGH_INTEG 或 LO_moderate_integ 常量。LO_ HIGH_INTEG 是缺省的数据完整性行为。
要获取关于数据完整性的更详尽用法,请参阅 数据完整性。
下列示例设置多个标志:
loDesc.setCreateFlags (IfxSmartBlob.LO_LOG+IfxSmartBlob.LO_TEMP+...)
并行 getXXX() 方法允许您取得大对象的当前存储特征:
public int getCreateFlags()
要获取关于所有特征的更详尽信息,请参阅《GBase 8s SQL 指南:语法》中描述 CREATE TABLE 语句的 PUT 子句的部分。
使用状态特征
IfxLoStat 类存储关于智能大对象的某些统计信息,诸如大小、最后访问时间、最后修改时间、最后状态更改,等等。下表展示您可取得的状态信息。
表 1. 智能大对象的状态信息
| 状态信息 | 描述 |
|---|---|
| 最后访问时间 | 最后访问智能大对象的时间,以秒计 仅当为智能大对象启用最后访问时间属性时,此值才可用。要获取更多信息,请参阅 最后访问时间。 |
| 最后更改时间 | 最后更改智能大对象的状态的时间,以秒计 状态更改包括元数据更改和用户数据更改(对引用数的数据更新和更改)。以从 19701 年 1 月 1 日以来的秒数来存储此系统时间。 |
| 最后修改时间 | 最后修改智能大对象的时间,以秒计 修改仅包括对元数据和用户数据的更改(数据更新)。以从 19701 年 1 月 1 日以来的秒数来存储此系统时间。 在某些平台上,最后修改时间可能还有微秒组件,可单独从秒组件取得它。 |
| 大小 | 智能大对象的大小,以字节计 |
| 存储特征 | 请参阅 使用存储特征。 |
要取得对状态结构的引用,请调用 IfxSmartBlob 类中的下列方法:
IfxLoStat IfxLoGetStat(int lofd)
要取得状态信息的特别分类,请调用下表中展示的方法。
表 2. 取得状态信息的方法
| 状态信息 | ifxLoStat 类中的方法签名 |
|---|---|
| 最后访问时间 | int getLastAccessTime() |
| 最后更改时间 | int getLastStatusTime() |
| 最后修改时间 | int getLastModifyTimeM() - 以微秒计的时间 int getLastModifyTimeS() - 取整到秒的时间 |
| 大小 | int getSize() |
| 存储特征 | ifxLobDescriptor getLobDescriptor() |
使用锁
要防止同时访问智能大对象数据,当打开智能大对象时,数据库服务器取得对此数据的锁。此智能大对象锁不同于以下种类的锁:
- 行锁
智能大对象上的锁不锁定智能大对象驻留其中的行。然而,如果您从行检索智能大对象,且该行仍为当前的,则数据库服务器可能持有行锁以及智能大对象锁。在智能大对象上持有锁,而不是在行上,因为许多列可能访问同一智能大对象数据。
- 在表的同一行中,不同智能大对象的锁
智能大对象上的锁不影响该行中的其他智能大对象。
下表展示智能大对象可支持的锁模式。
表 1. 智能大对象的锁模式
| 锁模式 | 用途 | 描述 |
|---|---|---|
| lock-all | 锁定整个智能大对象 | 指示锁请求适用于智能大对象的所有数据 |
| byte-range | 仅锁定智能大对象指定的部分 | 指示锁请求仅适用于指定字节数的智能大对象数据 |
当服务器打开智能大对象时,它使用下列信息来确定智能大对象的锁模式:
-
智能大对象的访问模式
数据库服务器取得如下锁:
- 在共享模式下,当打开智能大对象来读取时(read-only)
- 在更新模式下,当打开智能大对象来写时(write-only、read/write、write/append)
当在智能大对象上实际执行写操作(或某其他更新)时,服务器将此锁升级为排他锁。
-
当前事务的隔离级别
如果数据库表的隔离模式为 Repeatable Read,则服务器不释放它在智能大对象上取得的任何锁,直到事务结束为止。
在缺省情况下,服务器选择 lock-all 锁模式。
服务器保留该锁如下:
- 它持有共享模式锁和更新锁(其尚未升级至排他锁),直到发生下列事件之一为止:
- 智能大对象关闭
- 事务结束
- 显式的请求来释放锁(仅对于 byte-range 锁)
- 它持有排他锁,直到事务结束为止,即使关闭智能大对象也如此。
当发生前述条件之一时,服务器释放智能大对象上的锁。
即使智能大对象保持打开,在事务结束时,也会丢失锁。当服务器检测到智能大对象没有活动的锁时,当首次发生智能大对象访问时,它自动地取得新的锁。它取得的锁是基于智能大对象的原始访问模式的。
当当前事务终止时,服务器释放锁。然而,当执行下一需要锁的函数时,服务器再次取得锁。如果这不是期望的行为,则服务器侧 SQL 应用程序可使用 BEGIN WORK 事务阻塞,并在需要使用该锁的最后语句之后放置 COMMIT WORK 或 ROLLBACK WORK 语句。
byte-range 锁定
在缺省情况下,当数据库服务器需要锁定智能大对象时,它全部使用 lock-all 锁。lock-all 锁是一种 “全都或全不” 锁;也就是说,它们锁定整个智能大对象。当数据库服务器取得排他锁时,只要持有锁,其他用户就不可访问智能大对象的数据。
如果此锁定对于应用程序的并发要求过于苛刻,则可使用 byte-range 锁定,而不使用 lock-all 锁定。以 byte-range 锁定,您可指定在智能大对象数据中锁定的字节范围。如果其他用户访问该数据的其他部分,他们仍可获得自己的 byte-range 锁。
请使用 IfxSmartBlob 类中的 IfxLoLock() 方法,来指定 byte-range 锁定:
public long IfxLoLock(int lofd, long offset, int whence, long range, int lockmode) throws SQLException
要解锁该对象中的字节范围,请使用 IfxLoUnLock() 方法:
public long IfxLoUnLock( int lofd, long offset, int whence, long range) throws SQLException
lofd 参数是由 IfxLoCreate() 或 IfxLoOpen() 方法返回的定位器文件描述符。offset 参数是从开始的查找位置的偏移量。whence 参数标识开始的查找位置。在 智能大对象内的位置 中的表中描述这些值。
range 参数指示在智能大对象内要锁定或解锁的字节数。lockmode 参数指示要创建什么类型的锁。这些值可为IfxSmartBlob.LO_EXCLUSIVE_MODE 或 IfxSmartBlob.LO_SHARED_MODE。
高速缓存大对象
每当从数据库服务器访存 BLOB、CLOB、text 或 byte 类型对象时,就在客户机内存中高速缓存该数据。如果大对象的大小大于 LOBCACHE 环境变量中的值,则在临时文件中存储该大对象数据。要获取关于 LOBCACHE 变量的更多信息,请参阅 大对象的内存管理。
避免转移大对象的错误
在检查是否已发生了错误之前,使用 IFX_LOB_XFERSIZE 环境变量来指定从客户机应用程序向数据库服务器转移的 CLOB 或 BLOB 中的字节数。每转移指定的字节数,就发生错误检查一次。如果发生错误,则不发送剩余的数据,并报告错误。如果未发生错误,则继续文件转移,直到它结束为止。
例如,如果将 IFX_LOB_XFERSIZE 的值设置为 10485760(10 MB),则每发送 10485760 字节的 CLOB 或 BLOB 之后,会发送错误检查。如果未设置 IFX_LOB_XFERSIZE 环境变量,则在转移整个 BLOB 或 CLOB 之后发生错误检查。
IFX_LOB_XFERSIZE 环境变量的有效范围为从 1 至 9223372036854775808 字节。请在客户机上设置 IFX_LOB_XFERSIZE 环境变量。
您应调整 IFX_LOB_XFERSIZE 的值,以适应您的环境。请将 IFX_LOB_XFERSIZE 环境变量设置得足够低,以便于尽早检测到大型 BLOB 或 CLOB 数据类型的传输错误,但不要低得超出所消耗的网络资源。
智能大对象示例
下列示例说明本部分中讨论的一些任务。
创建智能大对象
此示例说明 创建智能大对象 中展现的那些步骤。
file = new File("data.dat");
FileInputStream fin = new FileInputStream(file);
byte[] buffer = new byte[200];;
IfxLobDescriptor loDesc = new IfxLobDescriptor(myConn);
IfxLocator loPtr = new IfxLocator();
IfxSmartBlob smb = new IfxSmartBlob(myConn);
// Now create the large object in server. Read the data from the
file
// data.dat and write to the large object.
int loFd = smb.IfxLoCreate(loDesc, smb.LO_RDWR, loPtr);
System.out.println("A smart-blob is created ");
int n = fin.read(buffer);
if (n > 0)
n = smb.IfxLoWrite(loFd, buffer);
System.out.println("Wrote: " + n +" bytes into it");
// Close the large object and release the locator.
smb.IfxLoClose(loFd);
System.out.println("Smart-blob is closed " );
smb.IfxLoRelease(loPtr);
System.out.println("Smart Blob Locator is released ");
将文件 data.dat 的内容写至智能大对象。
将数据插入至智能大对象
下列代码将数据插入至智能大对象:
String s = "insert into large_tab (col1, col2) values (?,?)";
pstmt = myConn.prepareStatement(s);
file = new File("data.dat");
FileInputStream fin = new FileInputStream(file);
byte[] buffer = new byte[200];;
IfxLobDescriptor loDesc = new IfxLobDescriptor(myConn);
IfxLocator loPtr = new IfxLocator();
IfxSmartBlob smb = new IfxSmartBlob(myConn);
// Create a smart large object in server
int loFd = smb.IfxLoCreate(loDesc, smb.LO_RDWR, loPtr);
System.out.println("A smart-blob has been created ");
int n = fin.read(buffer);
if (n > 0)
n = smb.IfxLoWrite(loFd, buffer);
smb.IfxLoClose(loFd);
System.out.println("Wrote: " + n +" bytes into it");
System.out.println("Smart-blob is closed " );
Blob blb = new IfxBblob(loPtr);
pstmt.setInt(1, 2); // set the Integer column
pstmt.setBlob(2, blb); // set the blob column
pstmt.executeUpdate();
System.out.println("Binding of smart large object to table is
done");
pstmt.close();
smb.IfxLoRelease(loPtr);
System.out.println("Smart Blob Locator is released ");
将文件 data.dat 的内容写至 large_tab 表的 BLOB 列。
从智能大对象检索数据
本主题中的示例说明 访问智能大对象 中的步骤。
下列代码示例展示如何使用 GBase 8s 扩展类来访问智能大对象数据:
byte[] buffer = new byte[200];
System.out.println("Reading data now ...");
try
{
int row = 0;
Statement stmt = myConn.createStatement();
ResultSet rs = stmt.executeQuery("Select * from demo_14");
while( rs.next() )
{
row++;
String str = rs.getString(1);
InputStream value = rs.getAsciiStream(2);
IfxBblob b = (IfxBblob) rs.getBlob(2);
IfxLocator loPtr = b.getLocator();
IfxSmartBlob smb = new IfxSmartBlob(myConn);
int loFd = smb.IfxLoOpen(loPtr, smb.LO_RDONLY);
System.out.println("The Smart Blob is Opened for reading ..");
int number = smb.IfxLoRead(loFd, buffer, buffer.length);
System.out.println("Read total " + number + " bytes");
smb.IfxLoClose(loFd);
System.out.println("Closed the Smart Blob ..");
smb.IfxLoRelease(loPtr);
System.out.println("Locator is released ..");
}
rs.close();
}
catch(SQLException e)
{
System.out.println("Select Failed ...\n" +e.getMessage());
}
首先,ResultSet.getBlob() 方法取得 BLOB 类型的一个对象。需要强制转型来将返回的对象转换为 IfxBblob 类型的对象。接下来,IfxBblob.getLocator() 方法从 IfxBblob 对象取得一个 IfxLocator 对象。在 IfxLocator 对象可用之后,您可实例化一个 IfxSmartBlob 对象,并使用 IfxLoOpen() 和 IfxLoRead() 方法,来读取智能大对象数据。访存 CLOB 数据是类似的,但它使用方法ResultSet.getClob()、IfxCblob.getLocator(),等等。
如果使用 getBlob() 或 getClob() 来从 BLOB 类型的列访存数据,则不需要使用前一样例代码那样的 GBase 8s 扩展来检索实际的 BLOB 内容。您可简单地使用 Java.Blob.getBinaryStream() 或 Java.Clob.getAsciiStream() 来检索内容。GBase 8s JDBC Driver 使用与样例代码相同的步骤,为您隐式地从数据库服务器取得内容。此方法比前一示例中的方法更简单,但不提供读取 BLOB 列内容的那么多选项。